/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Чтобы эффективно использовать информацию, которая накапливается в системах, ежедневно логируется и записывается в базы данных, необходимо тщательно анализировать и извлекать именно интересующие события, с заданным условиями и отвечающие определённым критериям для построения реальных отчётов. Важно чтобы информации было достаточно для анализа, в то же время данные не должны быть избыточными во избежание неоправданного усложнения анализа и увеличения временных затрат на его проведение.
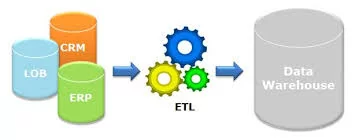
ETL это процесс первоначальной обработки и подготовки данных для последующего анализа. Он включает:
- Extract — получение информации из внешних источников (таблицы или файлы в которых данные разделены специальными символами-разделителями).
- Transform – трансформация данных. Тут выполняются основные манипуляции с данными, проводятся всевозможные преобразования исходных таблиц. С помощью различных инструментов выполняются операции агрегирования, удаления данных, добавления новых значений, фильтрация данных, сортировка и тд. На данном шаге формируются вспомогательные таблицы, создаваемые на время.
- Load – загрузка. Данные из промежуточных таблиц помещаются в хранилище данных или записываются в базу данных.
Pentaho – свободное программное обеспечение для бизнес-анализа. Один из модулей для интеграции исходных систем и хранилища – Pentaho Data Integration. Позволяет получать и объединять различные данные из любых источников, очищать исходные данные, удалять избыточную информацию. Удобный интерфейс для работы с данными, включает широкий спектр инструментов для их преобразования. Нет необходимости писать программный код, интуитивно понятные команды и графическая визуализация процесса преобразования упрощает работу с данными.
Оператор – это логическая единица, которая может производить какое-то действие над данными. Оператор имеет вход и выход. На входе поступают сырые данные, на выходе получаются обработанные данные. В Pentaho Data Integration реализован удобный поиск нужного оператора, весь список доступных для использования представлен в левом меню рабочего окна. Реализована технология Drag-and-Drop, доступно для выбора множество компонентов. Комбинируя их между собой можно строить и получать нужные трансформации исходных таблиц.
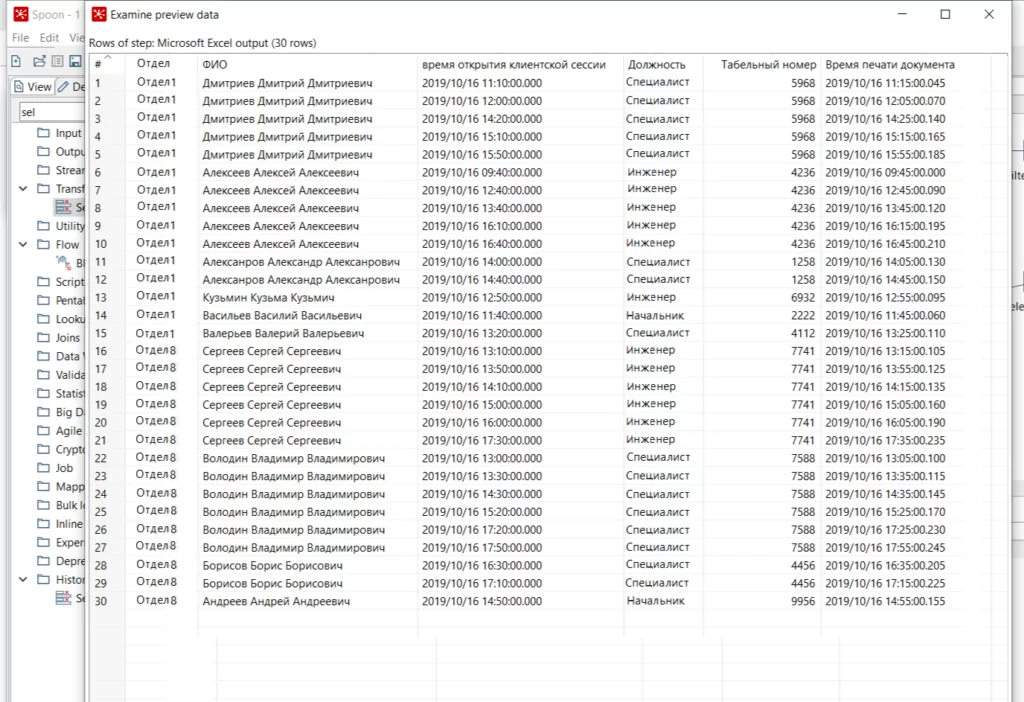
Кейс: необходимо получить выборку тех подразделений, в которых как минимум 2 сотрудника совершили 5 и более операций. В результирующей таблице должны быть следующие поля: ФИО, должность, табельный номер, наименование подразделения, время начала работы с клиентом, время печати документа. Исходные данные содержатся в трех разных таблицах.
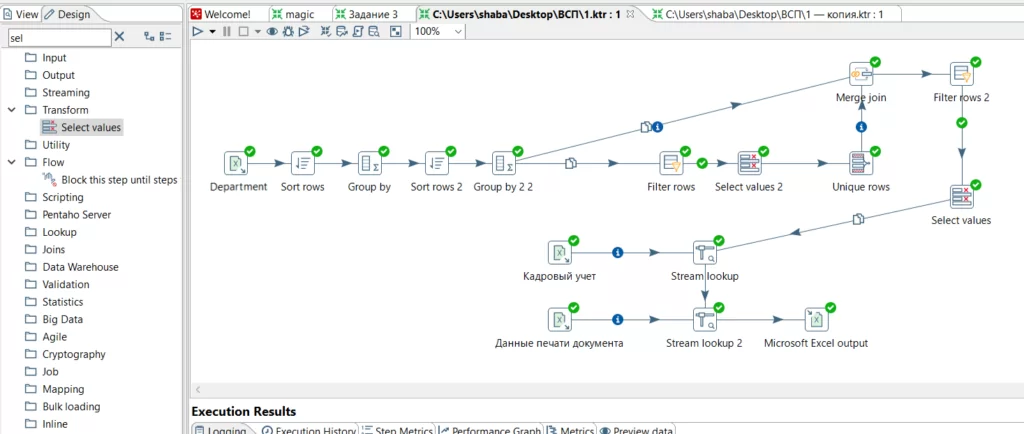
Для решения задачи последовательно выполняем операции сортировки и группировки, чтобы получить столбцы с информацией сколько в каждом подразделении сотрудников и сколько у них операций. Далее делаем фильтр записей для выбора отвечающих условию задачи. И выберем уникальные значения по полю подразделение. Получили список подразделений в которых больше 5 операций как минимум у 2 сотрудников.
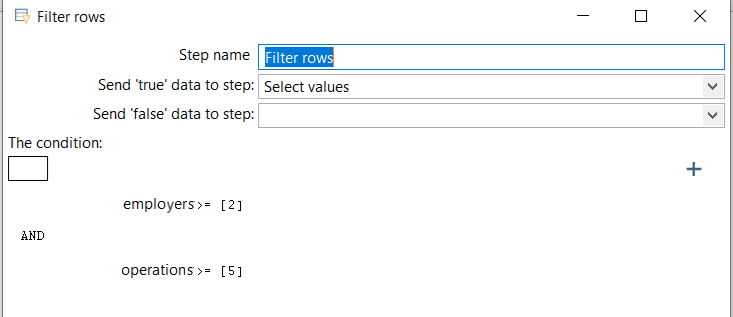
Затем нужно сопоставить полученные номера подразделений с исходной таблицей данных. Сделаем это оператором Merge join по полю наименование подразделения.
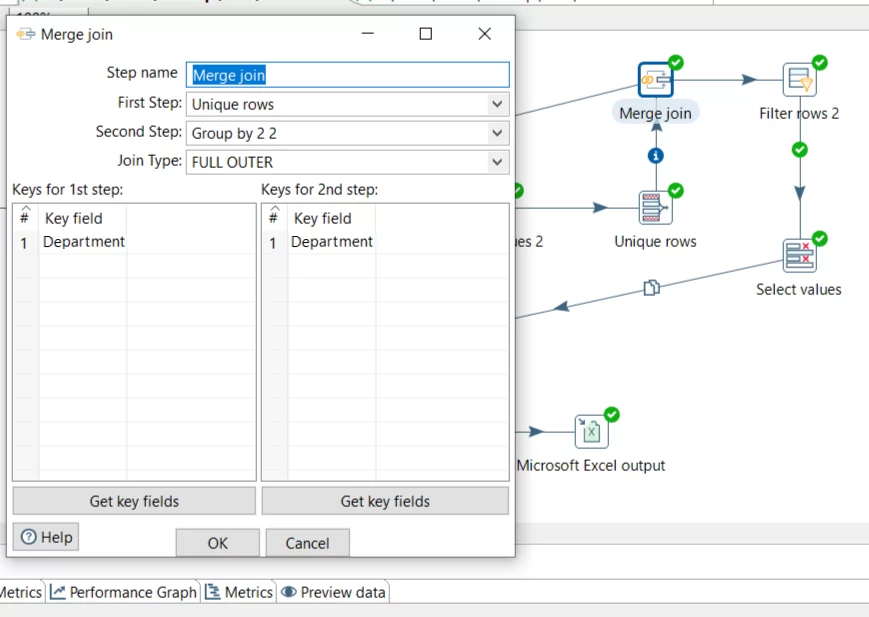
А затем фильтром уберём несовпавшие строки. В итоге останутся нужные записи таблицы.
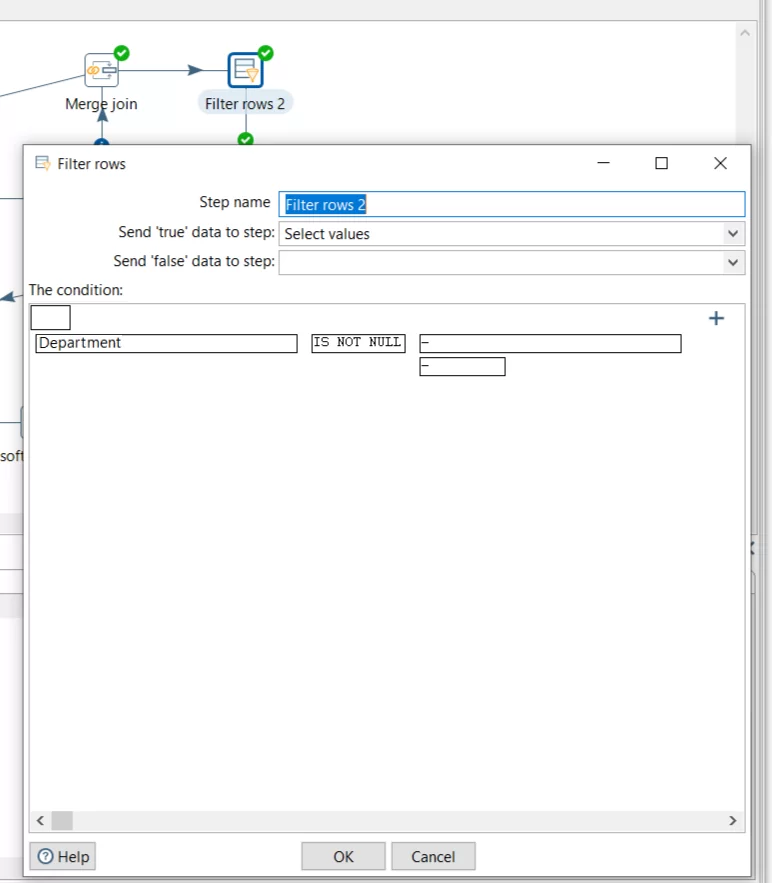
Останется только подтянуть недостающие данные из других исходных таблиц. Оператором Stream lookup последовательно добавим нужные поля, сопоставляя значения по полю ФИО и время открытия клиентской сессии.
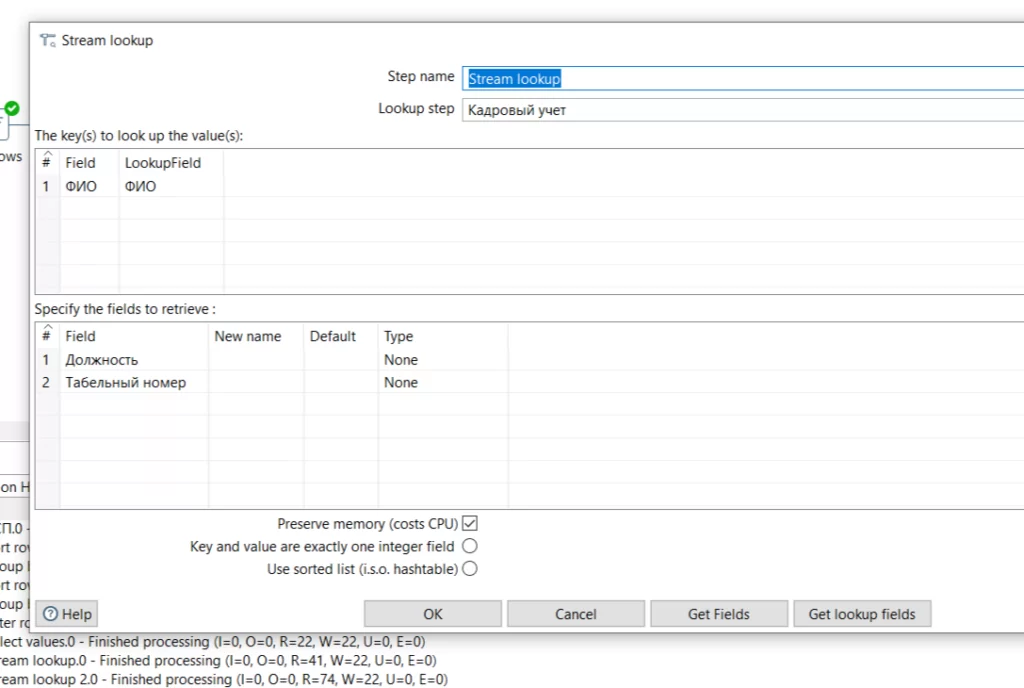
Получена итоговая схема процесса трансформации.
Результирующая таблица:
На практике часто возникают задачи выборки данных из разных источников. На мой взгляд, представленный инструмент интегрирования информации будет полезен в работе аудитора. Так как является бесплатным, позволяет открыть для редактирования все исходные данные в одном приложении и с лёгкостью объединить их в единую результирующую таблицу с требуемыми полями.