/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Сегодня мы поговорим об анализе текста. Нередко перед аудитором стоит задача обработать большой массив однотипного текста и выбрать/подсветить определенные фрагменты, которые будут использованы в аудиторском проекте.
Рассмотрим стандартную ситуацию, когда аудитору надо сделать и обработать подборку негатива СМИ по контрагентам. Если эта задача разовая, количество контрагентов не велико и анализируемый период достаточно короткий, то не стоит нагружать себя и готовить автоматизированное решение не имеет смысла. Поэтому данная информация будет интересна тем, кто планирует регулярно обрабатывать большие массивы информации.
Для успешного решения данной задачи необходимо выполнить 3 шага:
1 шаг. Получить информацию.
2 шаг. Убрать лишнее.
3 шаг. Сделать разметку.
Рассмотрим каждый из этих шагов более подробно.
1 шаг. Получить информацию.
Мы не планируем подробно останавливаться на рекомендациях по подбору и поиску информации по контрагенту. Будем считать, что массив данных для разметки у Вас уже сформирован и требуется его обработать. Данное предположение сделано поскольку каждый вправе выбрать наиболее приемлемый для себя источник информации:
— результаты запросов в поисковых системах (практически бесплатный, но наиболее трудозатратный вариант);
— выгрузки данных с помощью новостных агрегаторов (наиболее удобный и простой в применении, но достаточно дорогой способ, при этом для разовых работ можно воспользоваться тестовым доступом);
— внутренние источники в организации.
Для тестирования нашего алгоритма мы оформили тестовый доступ к новостному агрегатору, с помощью которого создали подборку СМИ из 6000 новостей за год по 300 компаниям, находящимся в фокусе внимания федеральных, региональных СМИ.
2 шаг. Убрать лишнее.
На этом шаге нам требуется качественно очистить выгруженную информацию от «мусора» или шумов.
На примере задачи с негативом СМИ по контрагентам можно выделить следующие виды шумов:
— информация, которая не соответствует контрагенту;
— информация дублируется;
— информация не является негативной.
Для решения задачи по очистке шумов мы применяли последовательно 4 алгоритма.
Для оптимизации работы рекомендуем сначала использовать быстрые алгоритмы, а более медленные ставить на последние этапы, когда объем обрабатываемой информации будет минимальным.
Алгоритм 1. Удаление дублей с использованием библиотеки Pandas, метод класса DataFrame – drop_duplicates()
Использование данной библиотеки позволяет удалить полные дубли по большому массиву информации менее чем за секунду, поэтому мы использовали ее в первую очередь.
На нашей тестовой выборке мы сократили объем информации подлежащей обработке почти в 2 раза за 16 мсек.
Пример кода:
data.drop_duplicates(subset='Выдержки из текста', inplace = True)
data.drop_duplicates(subset='Заголовок', inplace = True)Переменные:
— data – массив новостей;
— subset – колонка DataFrame, по которой метод определяет дубликаты.
Алгоритм 2. Удаление шумов не относящуюся к контрагенту.
В данном случае требуется использовать доступную информацию, полученную в ходе сотрудничества с контрагентом.
Для нашей тестовой выборки мы собрали информацию о территориях присутствия выбранных компаний из открытых источниках (официальные сайты компаний, информационные порталы с адресами и телефонами организаций).
После чего написали процедуру, которая удаляет новости по региональному признаку. На выходе у нас остались новости только всех федеральных СМИ и части региональных СМИ, в которых контрагент ведет деятельность.
Алгоритм работал чуть менее полминуты и сократил нашу подборку на 1000 новостей.
Для удаления шумов по территориальному признаку мы использовали стандартные процедуры циклов и ветвления. В цикле просматриваем регионы новостей и проверяем, ведет ли контрагент деятельность в этом регионе. На выходе получаем массив «флагов», по которому мы в дальнейшем фильтруем данные и избавимся от дубликатов.
Пример кода:
ter_data = pd.read_excel('Данные_о_территориальной_принадлежности_контрагента.xlsx')
#создадим список флагов
not_in_terr_flag = []
for row in range(data.shape[0]):
# id контрагента в массиве новостей
id_ka = data['id'].iloc[row]
# флаг "соответствия" региона новости региону контрагента
local_flag = 0
# далее идет сравнение
if data['Регион источника'].iloc[row] not in re.split('\\.| |,|\"|\)|\)',str(ter_data[ter_data.id == id_ka][['Регион', 'id']]).groupby('INN').sum().iloc[0,0]):
not_in_terr_flag.append(1)
continue
else:
not_in_terr_flag.append(0)Алгоритм 3. Удаление дублей побитовым методом.
Учитывая практику некоторых СМИ перепечатывать другие источники, внося незначительные изменения в текст, мы решили удалить дубли путем побитового сравнения текстов.
Наша тестовая процедура удаляет дублирующие новости, совпадающие побитово на 70 и более процентов при условии, что новости опубликованные в одну дату по одному контрагенту.
На тестовой выборке этот алгоритм работает чуть более 35 сек. и удаляет 174 дубля или 9% от своего входа.
В итоге наша исходная выборка сократилась до 1 139 новостей.
Для побитового метода были разработаны 2 функции:
— битовый поиск дубликатов, которая позволяет сравнить побитовые разложения двух слов,
— битовый поиск дубликатов по текстам, которая позволяет сравнивает два текста.
Пример кода:
# битовый поиск дубликатов
def word_duplicate(slovo_a, slovo_b, tolerance = .7):
local_match_counts = 0
for x, y in zip(bytearray(slovo_a, encoding='utf-8'),
bytearray(slovo_b, encoding='utf-8')):
if x == y:
local_match_counts+=1
if min(len(slovo_a),len(slovo_b)) > 0 and local_match_counts/min(len(slovo_a),len(slovo_b)) > tolerance:
return True
else:
return False
# битовый поиск дубликатов по текстам
def text_duplicate(text_a, text_b, tolerance = .7, w_tolerance = .7):
predlojenie_a = re.split('\\.| |,|\"|\)|\)', text_a)
predlojenie_b = re.split('\\.| |,|\"|\)|\)', text_b)
if len(predlojenie_a) > len(predlojenie_b):
predlojenie_a, predlojenie_b = predlojenie_b, predlojenie_a
counter = 0
for word_a in predlojenie_a:
for word_b in predlojenie_b:
if word_duplicate(word_a, word_b, w_tolerance):
counter += 1
break
else:
continue
if counter/len(predlojenie_a) > tolerance:
return True
else:
return False Параметры tolerance и w_tolerance позволяют регулировать «толерантность» к неполным дубликатам (в данном случае установлено значение 0.7, т.е. слова и предложения признаются дубликатами в случае совпадение на 70 и более процентов)
Алгоритм 4. Удаление дублей с использованием PyMorphy2.
Морфологический анализатор PyMorphy2 позволяет нормализовать формы слов и провести их последующее сравнение. Это наиболее медленный алгоритм в нашем арсенале, поэтому мы использовали его на последнем этапе. Логика нашей процедуры была такой – удаляем дублирующие новости, которые пословно совпадают на 70 и более процентов при условии, что они опубликованные в одну дату по одному контрагенту.
Работа этого алгоритма заняла более 8 часов и позволила удалить еще 363 дубля.
Основной продукт этого этапа — нормализованные формы слов, которые используются нами на этапе разметки.
Суть алгоритма предельно похожа на предыдущий, за исключением использования класса MorphAnalyzer() библиотеки PyMorpy2
Пример кода:
from pymorphy2 import MorphAnalyzer
mor_an = MorphAnalyzer()
# поиск дубликатов с помощью pymorphy
def morphy_word(first, second):
p = mor_an.parse(first)[0]
q = mor_an.parse(second)[0]
# учитываются только потенциально информативные части речи
if p.tag.POS in ['VERB','NOUN', 'ADJF','ADJS','PRTF','PRTS','INFN']\
and q.tag.POS in ['VERB','NOUN', 'ADJF','ADJS','PRTF','PRTS','INFN']:
if p.normal_form == q.normal_form:
return True
else:
return False
else:
return False
# поиск дубликатов текстов с помощью pymorphy
def morphy_text(first_sent, second_sent, tolerance = .7):
predlojenie_a = re.split('\\.| |,|\"|\)|\)', first_sent)
predlojenie_b = re.split('\\.| |,|\"|\)|\)', second_sent)
if len(predlojenie_a) > len(predlojenie_b):
predlojenie_a, predlojenie_b = predlojenie_b, predlojenie_a
counter = 0
len_sent = 1
for word_a in predlojenie_a:
p_new = mor_an.parse(word_a)[0]
if p_new.tag.POS in ['VERB','NOUN','ADJF','ADJS','PRTF','PRTS', 'INFN']:
len_sent += 1
for word_b in predlojenie_b:
dupl_word = morphy_word(word_a, word_b)
if dupl_word:
counter += 1
break
else:
continue
if counter/len_sent > tolerance:
return True
else:
return False 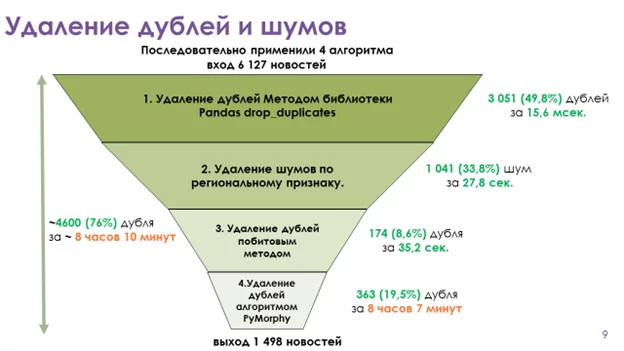
3 шаг. Сделать разметку.
На данном этапе необходимо создать «Мешок слов» и разработать пул правил для разметки текста.
Наполнить «Мешок слов» вы можете на свое усмотрение, в качестве примера рисковых событий могут быть выбраны фразы «Банкротство», «Ликвидация», «Долги», «Иски», «Акционерный конфликт».
Наш тестовый «Мешок слов» состоял из 90 слов, а алгоритм разметки позволял разметить новости по компаниям по 12 типам событий. Как я уже ранее писал, алгоритм разметки использует полученную на предыдущем этапе нормализованные тексты, на выходе мы получаем статьи, в которых упомянуты слова и/или словосочетания из «Мешка слов».
Из 1498 новостей, поступивших на обработку, на выходе осталось 136, соответствующих 12-ти выбранным типам событий.
Для алгоритма разметки мы использовали стандартные процедуры циклов и ветвления. Функция получает на вход предложение, ищет в нем слова из «Мешка» и возвращает их или сообщение об их отсутствии.
Пример кода:
def trouble_criteria(sentence):
data = re.split('\\.| |,|"', sentence)
target_words = []
for word_a in data:
p_new = mor_an.parse(word_a)[0]
if p_new.tag.POS in ['VERB', 'NOUN', 'ADJF', 'ADJS', 'PRTF', 'PRTS', 'INFN']:
for word_b in bag_of_words:
dupl_word = morphy_word(word_a, word_b)
if dupl_word:
target_words.append(word_b)
else:
continue
if target_words:
return set(target_words)
else:
return 'Критериев проблемности не обнаружено'Правильная последовательность применения алгоритмов для удаления дублей и шумов, грамотно составленный «Мешок слов» – вот залог успеха экспресс-обработки и разметки текста! Это позволит Вам существенно сократить количество часов монотонной работы высокооплачиваемых специалистов. Желаем Вам успехов на практике!