/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Как равномерно распределить потоки при загрузке данных?Если в наличии имеется отсортированный ID, то это решается довольно просто: путем деления количества строк на число потоков. А если такого ID нет? Приведен пример решения данной задачи, используя для разбиения на потоки поле с датой и временем.
Если при решении задачи ежедневной загрузки мы сталкиваемся с ситуацией, когда данные не успевает закончиться за отведенное время, стоит проверить, как изменится скорость выполнения задачи, если организовать загрузку, например, в 2 потока, разделив данные за день на наборы по 12 часов. Если увеличение числа потоков кратно уменьшает время загрузки, можно рассмотреть вариант решения, описанный ниже.
Для демонстрации примера, создадим таблицу, включающую в себя поле с типом данных datetime.
create table tst.TestTable (row_id int identity , row_date datetime) on [flg1] with (data_compression = page);Далее наполним таблицу случайно сгенерированными данными за 1 день (30 ноября 2020 г.). В примере описано заполнение таблицы числом строк равным 163845, переменная @i введена для организации счетчика цикла. Команда nocount on отключает вывод информации о вставленных строках на каждом этапе цикла.
set nocount on;
declare @i int
set @i = 1
while @i <= 163845 -- Число генерируемых строк
begin
insert into tst.TestTable(row_date) select cast(cast('2020-11-30' as nvarchar(10)) + ' ' + cast(cast(dateadd(second, - 10000000 * rand(),getdate()) as time(3)) as nvarchar(12)) as datetime2(3));
set @i = @i +1;
end
Выводим сгенерированные данные на экран (рис. 1).
select top 10 * from tst.TestTable;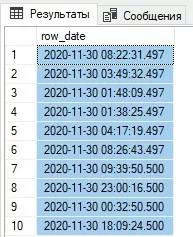
Далее для равномерного распределения данных по потокам нам нужно определиться с числом потоков (@flow_count, в нашем случае потоков 10) и посчитать общее число загружаемых строк (@kol). В первую очередь определяем шаг для потока, т.е. приблизительное число в нем строк (@step).
С помощью переменной @step мы сможем определить номер первой и последней строки каждого потока. Результаты данного разбиения занесем в таблицу @list_id, где поля:
- Flow_num – порядковый номер потока
- Begin_id – номер первой строки потока
- End_id – номер последней строки потока
- Step – приблизительное число строк потока
-- Объявление переменных
declare @kol int, @step int, @part int, @flow int, @flow_count int
declare @list_id table (flow_num int,begin_id int, end_id int, step int)
select @kol = count(*) from tst.TestTable; -- Общее число загружаемых строк
set @part = 1; -- id первой строки первого потока
set @flow = 1; -- порядковый номер потока
set @flow_count = 10 -- Число потоков загрузки
select @step = floor(cast(@kol as float)/cast (@flow_count as float)); -- Количество строк в 1 потоке
while @flow < @flow_count
begin
insert into @list_id select @flow [Flow_num], @part [BEGIN_ID], @part + @step -1 [END_ID], @step [STEP];
set @part = @part + @step;
set @flow = @flow + 1;
end
insert into @list_id select @flow [Flow_num], @part [BEGIN_ID], @kol [END_ID], @step [STEP];
Выводим на экран получившееся распределение потоков (рис. 2):
select * from @list_id;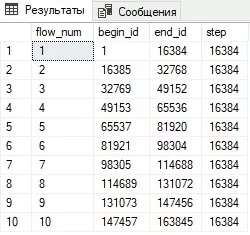
На данный момент определены границы потоков по номерам строк. Теперь нам необходимо искусственно сгенерировать идентификаторы строк для таблицы tst.TestTable и с помощью фильтра отобрать те из них, которые находятся на границах потоков. Результаты занесем в таблицу @flowlist, где поля:
- Row_date – время, обозначающее начало потока
- Flow_num – порядковый номер потока
- Begin_id – номер первой строки потока
- End_id – номер последней строки потока
- Step – приблизительное число строк потока
Идентификатор строки удобно сгенерировать с помощью оконной функции row_number(), однако сразу наложить фильтр на полученный ID мы не можем, поэтому в данном случае имеет смысл применение общего табличного выражения (CTE).
-- Объявляем таблицу, куда будет внесено время начала каждого потока
declare @flowlist table (row_date datetime, flow_num int, begin_id int, end_id int, step int)
-- Генерация ID
with cte as
(select row_date, row_number() over (order by row_date) row_num
from tst.TestTable)
-- Выбор времени, соответствующему ID на границе потока
insert into @flowlist
select cte.row_date,steps.*
from cte,@list_id steps
where cte.row_num = steps.begin_id;
Выведем на экран полученное время начала потоков (рис. 3):
select * from @flowlist;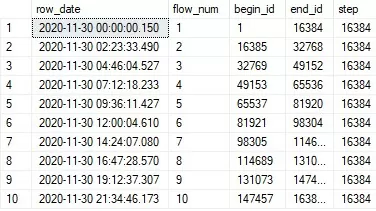
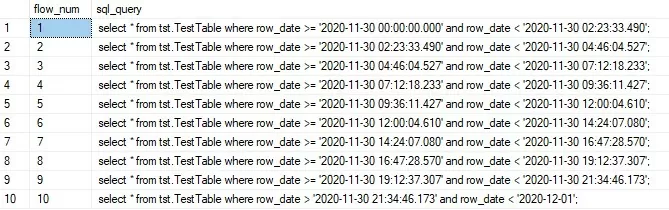
Граничащие значения времени получены, теперь можно приступить к генерации запросов для загрузки. Время начала первого потока заменим на начало загружаемой даты, а время окончания последнего будет строго меньше последующей даты. Генерация запросов будет выглядеть следующим образом.
select a.flow_num,'select * from tst.TestTable where row_date >= ''' + convert(nvarchar(30),iif(a.flow_num = 1,cast(a.row_date as date),a.row_date),121)
+ ''' and row_date < ''' + convert(nvarchar(30),b.row_date,121) + ''';'
sql_query from
@flowlist a
/*full*/ join @flowlist b
on a.flow_num = b.flow_num -1
union all
select a.flow_num, 'select * from tst.TestTable where row_date > ''' + convert(nvarchar(30),a.row_date,121)
+ ''' and row_date < ''' + convert(nvarchar(30), dateadd(day,1,cast(a.row_date as date)),121) + ''';'
from @flowlist a where a.flow_num = @flow_count
order by flow_num;
Результат выполнения запроса выше (рис. 4):
Меняя количество потоков ( @flow_count) с 10 на 5, получим следующие запросы (рис.5) :

Полученные код можно использовать как генератор для запросов для потоков при создании SSIS-пакетов для регулярной загрузки данных. Однако стоит помнить, что генерация ID с помощью оконной функции операция дорогостоящая, поэтому перед использованием код стоит протестировать на 1 дне данных Вашего источника. Рисунок 5 – Запросы при количестве потоков равным 5