/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
QlikSense (далее QS) – приложение, предоставляющее пользователю богатую коллекцию инструментов визуализации, исследования и анализа данных, поддерживающее интеграцию с различными источниками. Пользователь без специальных знаний легко сможет в несколько кликов загрузить данные и создать в нем свое первое приложение. Интерфейс при этом возьмет на себя всю “грязную” работу за пользователя и, в первую очередь, создаст скрипт загрузки данных из источника в собственное хранилище QS.
Созданный скрипт в упрощенном виде будет содержать следующие инструкции, в чем можно самостоятельно убедиться в меню “Редактор загрузки данных”:
LIB CONNECT TO <наименование подключения к источнику данных>;
[<псевдоним>]
LOAD <список полей>;
SELECT <список полей> FROM <схема таблица/представление/процедура источника>;
Вот тут и можно разглядеть потенциальную проблему, а именно ситуацию, когда таблица источника данных будет содержать действительно большое количество записей (например, 10 млн или больше) и при этом данные в источнике обновляются ежедневно. Ведь скрипт в этой редакции каждый раз инициирует их загрузку в полном объеме в хранилище QS. Становится очевидным, что такой подход работы с источником/базой данных, названный кстати “in-memory”, подойдет для относительно небольших уже подготовленных, сгруппированных и предварительно рассчитанных данных, но совершенно не годится для большого объема сырых данных.
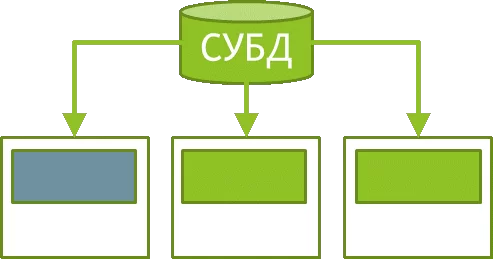
Вот было бы здорово, если бы был способ не загружать все эти столбцы/записи в QS и при этом иметь возможность обращаться за ними к источнику непосредственно при работе нашего приложения и при этом еще и переложить на СУБД источника расчет мер (агрегатов).
И оказалось, что о реализации такой возможности в QS позаботились и назвали эту технологию Direct Discovery.
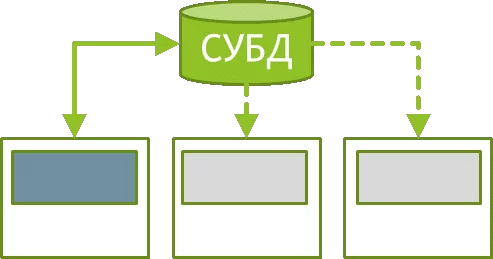
Итак, скрипт загрузки данных, созданный по — умолчанию с директивой LOAD, нам больше не подходит, его нужно исправить, чтобы задействовать технологию Direct Discovery:
LIB CONNECT TO <наименование подключения к источнику данных>;
DIRECT QUERY
dimension
<список полей измерений>
measure
<список полей мер>
detail
<список отображаемых полей>
FROM <схема таблица/представление/процедура источника>;
Под ключевым словом dimension указывается список полей, которые будут выступать в качестве измерений, т.е. полями группировки в приложении QS. При выполнении скрипта загрузки именно они и только их уникальные значения из базы данных будут загружены в хранилище QS.
Рассмотрим на простом примере.
Предположим, что есть большой журнал операций за год на 100 млн. строк и я хочу группировать в своем приложении операции по дате и виду операции. Тогда, с применением подхода Direct Discovery, в QS будут загружены только 365 строк с датами и некоторое количество строк с видами операций (например, 100 шт.), которые встречаются в таблице. При этом на этапе загрузки выделение уникальных значений полей (distinct) выполняет СУБД, а в QS уже передаются подготовленные данные.
В разделе detail указываются поля, которые можно будет отобразить в табличных виджетах приложения QS, значения этих полей предварительно не загружаются в QS, а вычитываются из источника уже во время работы приложения (отображения таблиц).
В разделе measure нужно указать список числовых полей, которые используются приложением QS в расчете мер. При этом вычисление агрегата (sum, mean, min, max, count и т.д.) осуществляется также на стороне СУБД на этапе отображения значения меры в приложении QS.
Как видите, многие задачи при таком подходе делегируются СУБД, разгружая сервер QS и экономя сетевой трафик. Конечно, в таком случае многое зависит уже от производительности СУБД.
А что там со сравнением отзывчивости интерфейса при работе приложений, использующих разные походы? Для проверки я создал два приложения с одинаковым функционалом, но разными подходами работы с одним и тем же источником данных (в моем случае это таблица в GreenPlum). Разницы в скорости работы приложений совершенно не почувствовал, а вот время загрузки данных по понятным причинам при использовании Direct Discovery оказалось в 10-15 раз меньше и разрыв только увеличивался при добавлении новых данных в источник.
Подводя итоги, приведу сравнительную таблицу рассмотренных походов:
| In-Memory | Direct Discovery | |
| Использование | По умолчанию | Требуется настройка скрипта загрузки |
| Загрузка данных в хранилище QS, потребление памяти | Полностью/Высокое потребление | Малая часть (только уникальные значения измерений)/Низкая |
| Скорость/работа приложения зависит от СУБД | Нет | Да |
| Расчет агрегата (меры) | QS | СУБД |
| Сортировка, distinct при загрузке | QS | СУБД |
| Нагрузка на процессор QS | Выше | Ниже |
| Базовая инструкция | LOAD | DIRECT QUERY |
Обе технологии имеют как преимущества, так и недостатки и при разработке в QS нужно применять наиболее подходящий в конкретной ситуации подход, и конечно же ничто не мешает комбинировать их в одном приложении.