/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 2 мин.
С помощью данной диаграммы можно сразу увидеть, какой процент задач выполнено за интересующий промежуток времени. Например, у нас есть логи исполнения задач, длительность которых установлена нормативным документами, используя данный код, вы сможете сразу увидеть процент задач с отклонениями.
Приступим к реализации, необходимо, чтобы это была функция, в которую мы передаем датафрейм с логом процесса и порог отсечения по времени, которое нас интересует. Для начала импортируем необходимые библиотеки и читаем файл с данными.
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter
df=pd.read_csv(‘log.csv’,sep = ‘;’)
Датафрейм должен содержать всего 2 столбца: идентификатор события и время совершения активностей, остальные имеющиеся данные для решения этой задачи нам не нужны.
Для подсчета эффективности процесса нам нужно получить:
- длительность каждого события в столбце ‘delta’, в который мы записываем разность максимального и минимального времени в рамках каждого события.
- столбец ‘count’ в который записываем количество активностей, завершившихся в рамках каждого значения ‘delta’.
- после этого формируем новый набор данных из уникальных сочетаний ‘delta’, ‘count’, и сортируем данные по количеству.
- создаем признак ‘cum percentage’, который будет считать процент выполненных задач с нарастающим итогом.
- строим 2 графика с наложением друг на друга. Первый представляет из себя столбчатую диаграмму, которая отражает количество задач за время, второй – линия, показывающая динамику процента исполнения задач.
Полный код функции и ее вызова:
def create_pareto_diagram(start, period, trash):
start['max_time'] = start.groupby(‘id_column’)[‘dt_column’].transform('max')
start['min_time'] = start.groupby(‘id_column’)[‘dt_column’].transform('min')
start['delta']=(start['max_time']-start['min_time']).astype('timedelta64['+period+']')
uniq=start[['id_column','delta']].drop_duplicates()
uniq['count'] = uniq.groupby('delta')['id_column'].transform('count')
uniq=uniq[['delta','count']].drop_duplicates()
uniq = uniq.sort_values(by='count',ascending=False).reset_index()
uniq["cum percentage"] = uniq['count'].cumsum()/uniq['count'].sum()*100
uniq=uniq[uniq['delta']<trash]
fig, ax = plt.subplots(figsize=(20,10))
ax.bar(uniq.index, uniq['count'], color="C0")
ax2 = ax.twinx()
ax2.plot(uniq.index, uniq["cumpercentage"], color="C1", marker="D", ms=1,label=uniq["cumpercentage"])
ax2.yaxis.set_major_formatter(PercentFormatter())
ax.tick_params(axis="y", colors="C0")
ax2.tick_params(axis="y", colors="C1")
plt.grid()
for tick in ax.get_xticklabels():
tick.set_rotation(45)
plt.show()
create_pareto_diagram(df, ‘m’, 80)
Обратите внимание на параметры period, trash. В данной функции period отвечает за значения в параметре ‘delta’, вы можете выбрать любой период значений в формате timedelta64[‘+period+’] (н-р секунды, дни, месяцы), а параметр trash отсекает с графика значения, выше заданного порога в выбранном периоде.
Посмотрим на результаты вызова функции
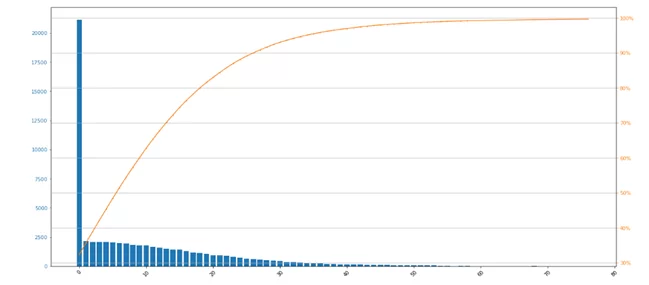
Нас интересует превышение времени исполнения задачи, которая должна быть выполнена за 10 минут. Здесь мы видим, что за первые 10 минут процесс завершается только в ~ 60% случаев, т.е. имеем отклонения в 40% случаях.
Попробуйте этот код на своих данных и найдите отклонения.