/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Классическая задача Computer Vision – задача распознавания и сегментирования. Это когда на фотографии или видео распознается объект и выделяется область, в которой он находится. Для ряда прикладных задач этого достаточно, но встречаются задачи, где помимо расположения человека важно проанализировать положение его тела, т.е. позу. Эффективно и просто справиться с этой задачей поможет инструмент OpenPose.
Зачем это
Анализ видео и изображений – одно из основных направлений применения технологий ML. Распознавание лиц и объектов позволяет автоматически анализировать данные, определяя положение тела, личность или даже эмоции человека, что может быть использовано как в системах безопасности — face id, определение действий человека, так и для улучшения клиентского опыта – детектирование эмоций клиентов и персонала.
Но каждый, кто писал программы распознавания объектов, используя opencv, знает, что выделение опорных точек и построение выпуклой оболочки — наименьшего выпуклого множества, содержащего опорные точки, дело часто тяжелое и неблагодарное.
Для примера попробуем выделить опорные точки на изображении.
image = cv.imread(“C:/Users/User/anaconda3/libs/openpose/examples/media/COCO_val2014_000000000192.jpg”)
im = image.copy() / 255.
im = im / 255
im = rgb2gray(im)
contours, hierarchy = cv2.findContours(img_as_ubyte(im), cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
ma = 0
cnt = 0
for cont in contours:
ar = cv2.contourArea(cont)
if ma < ar:
ma = ar
cnt = cont
hull = cv2.convexHull(cnt, returnPoints = False)
defects = cv2.convexityDefects(cnt,hull)
m = cv2.moments(cnt)
cx = int(m[“m10”]/m[“m00”])
cy = int(m[“m01”]/m[“m00”])
fng = []
for point in defects:
point = point[0]
s, e, f = cnt[point[0]][0], cnt[point[1]][0], cnt[point[2]][0]
d = point[3] / 256.0
fng.append([tuple(s), tuple(e), tuple(f), d])
for point in fng:
cv.circle(image, point[0], 5, [255,0,0], -1)
cv.circle(image, point[1], 5, [255,0,0], -1)
cv. circle(image, point[2], 5, [255,1,0],-1)

Для этого сначала лучше преобразовать изображение – нормализовать и перевести в серый, после этого определить контуры, построить выпуклую оболочку и вывести на изображение опорные точки. Чтобы узнать позу человека, необходимо связать только крайние точки тела, к тому же с ближайшими соседями. А если на изображении видно не все тело?
Как можно заметить, работы вагон и маленькая тележка. Так что обратимся к существующим решениям.
Что это
OpenPose является первой системой для обнаружения человеческого тела в многомерном пространстве в реальном времени — всего 135 ключевых точек. Ключевые точки человеческого тела обычно соответствуют суставам с определенной степенью свободы на человеческом теле, таким как шея, плечо, локоть, запястье и т.д.
Модель была предложена исследователями из Университета Carnegie Mellon. На сегодняшний день OpenPose используется компанией Disney для точной передачи позы человека персонажами, а сами создатели алгоритма из Carnegie Mellon University даже научили робота копировать движения человека, а ученые из Университета Женевы использовали алгоритм для диагностики аутизма у детей.
Как оно работает
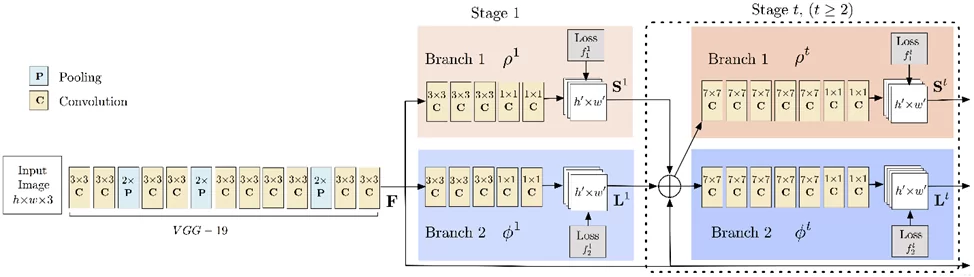
Вход модели представляет собой цветную картинку размера h*w.
Далее следуют 10 слоев VGGNet (Very Deep Convolutional Network), которые используются для создания карты признаков (feature maps) входного изображения.
Затем карта признаков обрабатывается в многоэтапном конвейере CNN (Convolutional neural network) для создания карт достоверности (Confidence Maps) и поля сходства деталей (Part Affinity Fields).
Карта достоверности — набор матриц или «тепловая карта» для каждой ключевой точки. Каждая матрица отражает достоверность появления определенной ключевой точки в пикселе. Чем выше значение на карте, тем выше вероятность появления опорной точки в этой части изображения.
Поле сходства деталей – набор матриц, который отражает степень близости для найденных ранее опорных точек и отвечает за кодирование 2D-вектора положения и направления конечностей в области изображения.
После получения карт достоверности (Confidence Maps) и поля сходства деталей (Part Affinity Fields) используют Венгерский алгоритм (Двудольное соответствие в теории графов — максимальное количество совпадений ребер среди всех совпадений графа), чтобы найти связь частей и соединить суставы одного и того же человека. Из-за векторной природы самого PAF, сгенерированные совпадения объединяются общий скелет человека.
Пример использования
Скачиваем последнюю версию библиотеки с github.
- OpenPose можно запустить из командной строки, указав путь к изображениям или видео:
bin\OpenPoseDemo.exe --image_dir examples\media\Программа сама откроет окно с результатами:

2. Или работать с ним как с обычной библиотекой.
Указываем путь до директории с библиотекой и импортируем ее:
sys.path.append(dir_path + ‘/../../python/openpose/Release’);
os.environ[‘PATH’] = os.environ[‘PATH’] + ‘;’ + dir_path + ‘/../../x64/Release;’ + dir_path + ‘/../../bin;’
import pyopenpose as op
Запускаем модель, передав ей необходимые параметры:
# Starting OpenPose
opWrapper = op.WrapperPython()
opWrapper.configure(params)
opWrapper.start()
Приступаем к обработке изображения:
# Process Image
Datum = op.Datum()
imageToProcess = cv2.imread(args[0].image_path)
datum.cvInputData = imageToProcess
opWrapper.emplaceAndPop(op.VectorDatum([datum]))
Выводим изображение с добавлением полученных опорных точек:
# Display Image
print(“Body keypoints: \n” + str(datum.poseKeypoints))
cv2.imshow(“OpenPose 1.7.0 – Tutorial Python API”, datum.cvOutputData)
cv.waitKey(0)
OpenPose способен детектировать позы сразу нескольких людей на изображении, способен покадрово обрабатывать видео, распознавать точки на лице или пальцах рук. При этом модель, как было показано выше, является невероятно простой в использовании, избавляя от необходимости самому разбираться с opencv и отбором необходимых точек.