/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В этой статье я расскажу о своем опыте решения задачи. О том, как распознать определенный объект в видеопотоке.
Исходные данные
Входными данными для анализа являются видеозаписи с регистраторов. Они выгружаются в форматах mp4 и avi (в зависимости от модели оборудования). Разрешение изображения от 720*576 до 1920*1080, в зависимости от настроек регистратора и параметров используемых камер.
С целью ускорения обработки данных — исходное видео предварительно преобразовывалось в набор «ключевых» кадров. Для этого использован свободно распространяемый инструмент ffmpeg – набор свободных библиотек с исходным кодом, которые позволяют записывать, конвертировать и передавать цифровые аудио- и видеозаписи в различных форматах:
ffmpeg -i convertedFile -vf select=eq(pict_type\, I) -vsync vfr savedDir frame-%05d.png
Предварительная обработка видео в дальнейшем позволила существенно снизить время на анализ данных (количество кадров уменьшилось примерно на 96%).
Выбор модели
Существуют различные методы для распознавания объектов на изображении. При этом наибольшей популярностью пользуются сверточные нейронные сети (Convolutional Neural Networks, CNN) и их модификации. Благодаря своей архитектуре они хорошо справляются с извлечением признаков из изображения. Есть несколько популярных архитектур CNN для распознавания образов: R-CNN, Fast R-CNN, Faster R-CNN, RetinaNet, SSD, YOLO и другие.
Я выбрал архитектуру YOLOv3 (You Only Look Once). Она обладает более высокой скоростью обработки данных, по сравнению с другими, при сопоставимом качестве. Данная сеть применяется ко всему изображению сразу, разделяя его своеобразной решеткой на несколько участков, и для каждого из них дает предсказание ограничивающих прямоугольников и вероятность нахождения искомого объекта (рис.1):
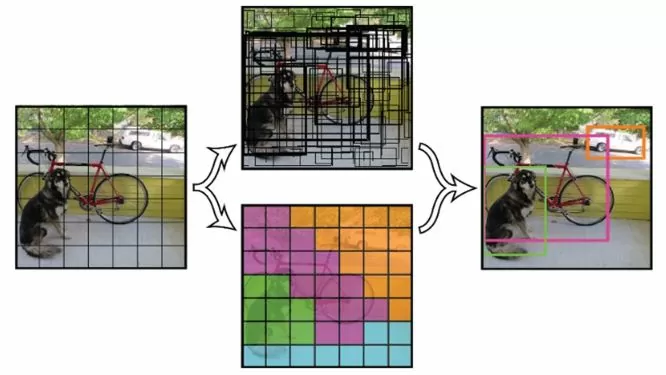
Для алгоритма задается порог обнаружения, чтобы формировать вывод только объектов с высокой вероятностью детектирования (рис.2):

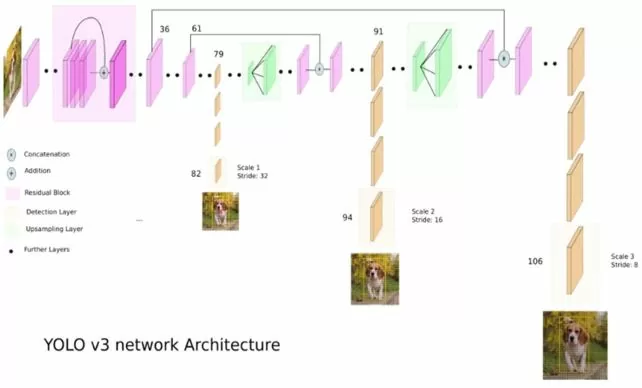
YOLOv3 является улучшенной версией архитектуры YOLO. Она состоит из 106 сверточных слоев и лучше детектирует небольшие объекты. Это связано с тем, что на выходе сети имеются три слоя, каждый из которых предназначен для обнаружения объектов разного размера. Ниже представлено схематичное изображение данной архитектуры (рис.3):
Подготовка модели
В принципе, для старта распознавания объектов с использованием архитектуры YOLO достаточно скачать с официального сайта проекта файл с предварительно обученной моделью[1] и использовать ее в своей программе. Если необходимо распознавание каких-то специфических объектов, либо нужно повысить качество модели, ее можно доучить на собственных данных.
Я взял модель, предварительно натренированную на ImageNet, и провел ее дополнительное обучение на изображениях из открытого датасета Google OpenImages v4[2], который был расширен при помощи самостоятельно собранного датасета.
В связи с тем, что для обучения модели необходима мощная рабочая станция, я воспользовался Google Colaboratory – бесплатным облачным сервисом компании Google, направленном на упрощение исследований в области машинного и глубокого обучения. В рамках этого сервиса можно получить удаленный доступ к рабочей станции, оснащенной двумя процессорами Intel Xeon 2.3 GHz, 12 Гб оперативной памяти и видеокартой Tesla T4, что позволяет с удобством обучать глубокие нейронные сети. На рабочей станции установлена операционная система Ubuntu 18.04, имеется возможность установки необходимых пакетов python и подключения Google Drive. Следует иметь ввиду, что один сеанс работы с сервисом не может превышать 12 часов, поэтому при длительной обработке данных необходимо сохранять промежуточные результаты, например, на Google Drive.
Для загрузки необходимых изображений из датасета Google OpenImages я использовал открытый инструмент OIDv4_Toolkit, позволяющий выбрать необходимые для загрузки классы и метаданные. После скачивания изображений проверил их на наличие «заглушек»[3], означающих, что исходное изображение было удалено, и исключил их из датасета. Затем дополнил датасет набором самостоятельно сделанных фотографий, на которых присутствуют детектируемые объекты. Полный датасет содержал около 4,7 тысяч изображений.
После разделения данных на обучающую, тестовую и валидационную выборки я запустил обучение модели. Процесс занял около 6 часов. В результате был получен файл, содержащий веса обученной модели (у меня он получился объемом около 240 Мб). Проверка модели на реальных данных показала ее работоспособность – необходимые объекты успешно детектировались.
Заключение
Предлагаю воспользоваться моим опытом по использованию открытых инструментов и сервисов, позволяющих решать задачи машинного обучения.
[1] В зависимости от задачи можно выбирать из моделей разного объема с разным качеством
[2] В настоящее время актуальна пятая версия датасета
[3] Стандартное изображение-заполнитель