/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Мой практический опыт показал, что для написания парсера приходится не только знать чуть больше, чем основные команды целевых библиотек Python, но и алгоритмы отлова ботов, методы их обхода, а также хорошо ориентироваться в разметке целевого сайта. И даже узнав и проделав всё это, готовый парсер является одноразовым инструментом.
На данный момент на рынке существуют готовые инструменты для парсинга, не многие из них оптимальны, но один отличается в лучшую сторону. Octoparse — это условно бесплатное приложение для извлечения веб-данных. Даже обычные пользователи могут легко использовать Octoparse для массового извлечения информации с веб-сайтов, без написания собственного кода и даже без просмотра кода сайта. Иногда он позволяет в разы упростить и ускорить получение данных.
По сравнению с конкурентами данный инструмент обладает невероятно прогрессивным и интуитивным интерфейсом, который визуализирует порядок действий на веб-сайте. Программа может автоматически извлекать желаемый контент почти с любого веб-сайта и после позволяет сохранять его в виде структурированных файлов в выбранном формате. На этом его достоинства не заканчиваются, Octoparse как и некоторые другие инструменты позиционирует выбираемые пользователем данные как совокупность повторяющихся элементов с похожими шаблонами HTML.
Я часто использую его в работе, например, для получения цен товаров из интернет-магазинов для последующего сравнения с закупочной стоимость.
Предлагаю инструкцию для работы с данным приложением.
Установка
Для начала нам потребуется зарегистрироваться на сайте https://www.octoparse.com (официальный сайт продукта Octoparse)
При входе нас встречает стартовая страница, выбрав пункт «Start a Free Trial» сайт перенаправит нас на форму регистрации.
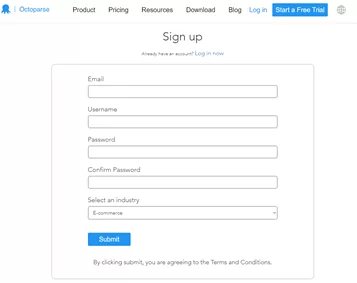
На странице регистрации мы видим классические поля для заполнения, такие как почтовый адрес, имя пользователя пароль, а также сфера использования данного продукта.
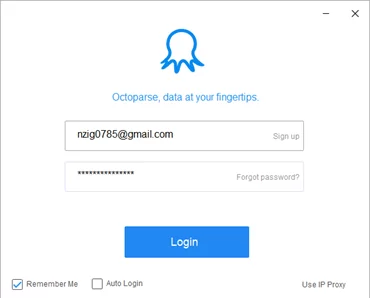
После регистрации на сайте на почтовый ящик придет письмо с подтверждением регистрации. Перейдя по ссылке в письме, мы активируем акант, и получим доступ к скачиванию программы. После скачивания и установки программу можно использовать.
Начало работы
Шаг 1: Аутентификация
При первом входе нас встречает окно авторизации, где необходимо ввести данные, использованные при регистрации на сайте и нажать “Logon”, так же можно нажать флажок “Auto Logon” для автоматической авторизации по этим учетным данным.
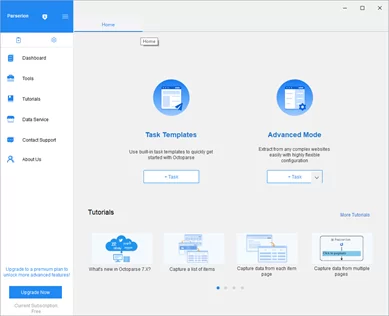
Шаг 2: Создание нового проекта
После авторизации перед мы увидим главное меню программы с множеством кнопок, выбираем кнопку “Task” под надписью ”Advanced Mode”.
Шаг 3: Выбор сайта для парсинга
После нажатия кнопки появляется окно ввода адреса веб-страницы, где необходимо ввести адрес нужной страницы и нажать кнопку «Save URL».
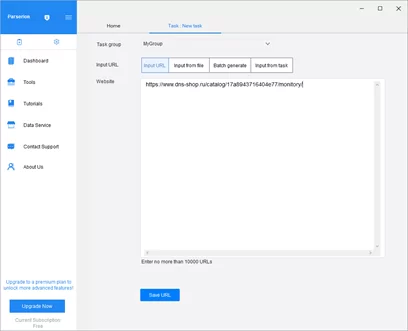
Для примера был использован сайт магазина «DNS:
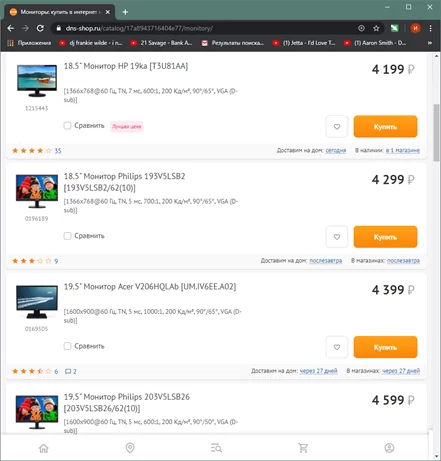
Шаг 4: Переход по страницам сайта После загрузки сайта программой он появится в нижней части экрана. Первым шагом необходимо создать цикл перехода между страницами, чтобы данные загружались не с одной страницы, а со всех страниц в нужной категории. Для этого в нижней части экрана, нажимаем кнопку перехода на следующую страницу сайта, и перед нами предстает контекстное меню, где нужно выбрать пункт “Loop click the selected link”.
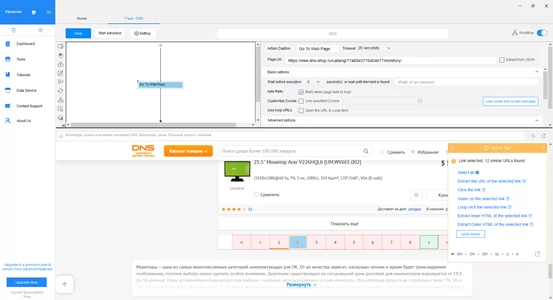
Шаг 5: Проверка плана выполнения После этого в левом верхнем углу на плане выполнения отобразится созданный цикл.
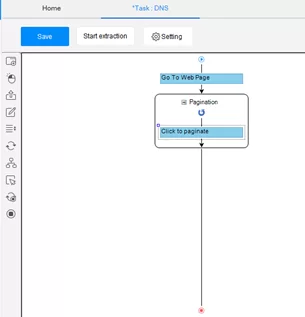
Шаг 6: Выбор данных
Перейдем к выбору необходимых для извлечения данных, нажав на интересующий элемент, в нашем случае — название модели монитора, перед нами снова предстанет контекстное меню, где мы можем нажать пункт “Select all” для выбора всех аналогичных элементов на странице.
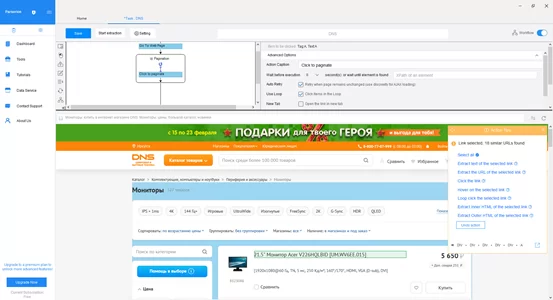
Шаг 7: Проверка выбранных данных
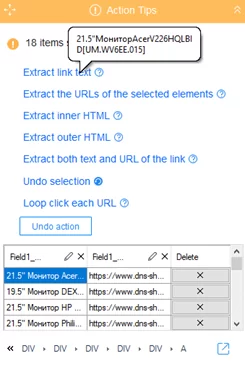
После выбора элементов в контекстном меню отобразится таблица с примером данных выбранной страницы, где мы можем удалить не нужные столбцы и строки. После выбора столбцов, нажимаем кнопку “Extract link text” для сохранения выбора.
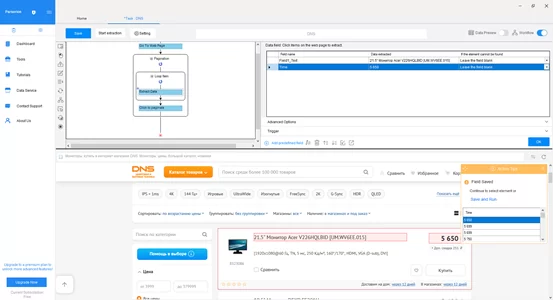
Шаг 8: Структурирование выбранных данных
После этого план выполнения изменится и внутри цикла перехода между страницами отобразится цикл извлечения данных. Далее выбрали цены по аналогичному алгоритму. В верхней правой части программы появилось окно работы с данными где мы можем совершить необходимые преобразования, например, переименовать название столбца.
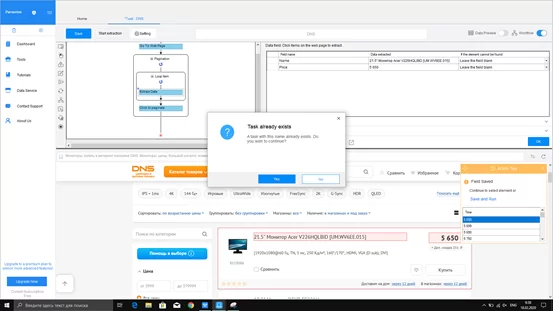
Шаг 9: Извлечение данных
Переходим к извлечению, нажав кнопку “Start extraction”, появится модальное окно для проверки готовности, подтверждаем “Yes”.
После появится окно с типом выгрузки, т.к. у меня нет личного сервера, поэтому я выбрал “Local extraction”
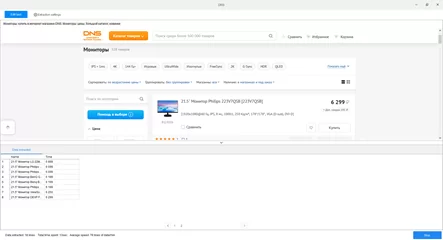
Далее в окне извлечения данных, в верхней части в реальном времени отображаются действия программы на сайте, а в нижней части отображаются извлеченные данные.
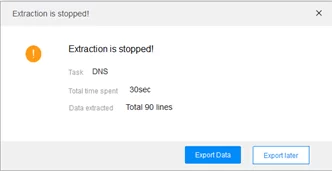
По завершению извлечения отображается общая статистика парсинга и программа предлагает экспортировать данные, что мы и сделаем, нажав кнопку “Export data”
Шаг 10: Экспорт данных
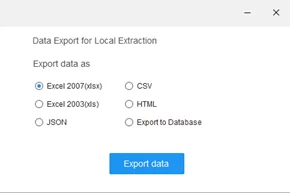
Выберем удобный нам формат и нажмем “Export data”
Шаг 11: Сохранение данных
Программа предложит выбрать место для сохранения и имя файла.
Выбрав место, программа производит экспорт с отображение хода выполнения. По завершению нажимаем “Finish”.
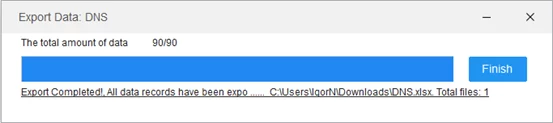
Шаг 12: Проверка результата
Проверим результат, открыв сохраненный файл, и о чудо, мы спарсили сайт без единой строчки кода.
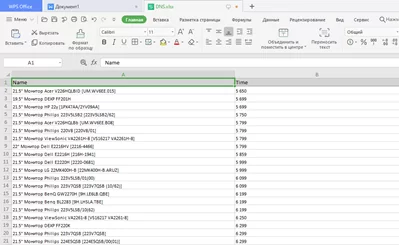
У всего есть свои минусы, у Octoparse — это ограничение количества загруженных строк с данными в 10000 записей для одного проекта, и ограничения по количеству проектов для одной учетной записи в 10 проектов. Однако всегда можно совершенно бесплатно зарегистрировать новый аккаунт и продолжить использование. Однозначно советую всем данный инструмент для небольших проектов как отличную альтернативу написанию кода. Если данный метод Вам помог получить данные поделитесь им с друзьями, коллегами.