/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Рассмотрим ситуацию, когда нужно обработать много данных за короткий промежуток времени. Мне необходимо было выбирать из таблицы базы данных все записи, каждая из которых содержит ссылку (url) на веб-страницу, а затем по каждой ссылке осуществить http-запрос и обработать полученные данные. Все ссылки ведут на страницы одного сайта, которые имеют одинаковую DOM-структуру.
Я написал алгоритм, перебирающий в цикле все ссылки, совершая синхронные http-запросы и обрабатывая результат. Однако, с ростом количества записей в таблице данный код работал всё медленнее и медленнее т.к. база данных пополнялась ежедневно и возрастало число ссылок, по которым необходимо совершить запрос.
Всё дело в том, что при совершении синхронного http-запроса поток, выполняющий код, останавливается, ожидая получения ответа от сервера. Поэтому, чем больше запросов нужно совершить, тем дольше будет суммарное время ожидания ответа от сервера.
Ускорить такую программу можно путём применения асинхронных запросов. Не стоит путать это с параллельным выполнением кода в разных потоках. При асинхронном подходе код также выполняется в одном потоке, однако, при совершении запроса, поток продолжает выполняться, пока не получит ответ от сервера (Рис. 1):
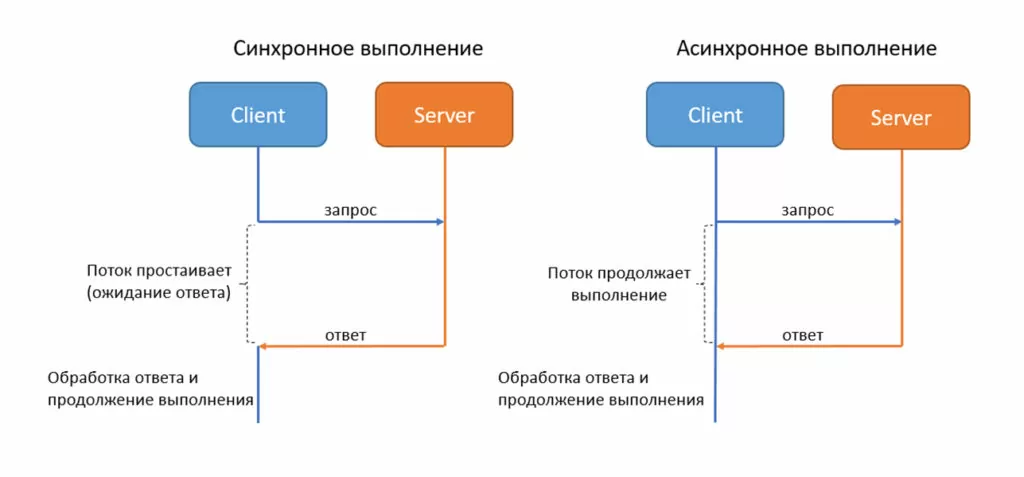
Это позволяет избежать простоев потока исполнения, сократив время выполнения программы. Приведу пример кода на языке php, реализующего данный механизм. Для выполнения асинхронных запросов применяется библиотека Guzzle (https://docs.guzzlephp.org):
<?php
use GuzzleHttp\Client;
use GuzzleHttp\Exception\RequestException;
use GuzzleHttp\Pool;
use GuzzleHttp\Psr7\Request;
use GuzzleHttp\Psr7\Response;
// Массив url ссылок, сформированный ранее
$Urls = [...];
$Client = new Client();
$Requests = function(&$a_urls){
for($i = 0; $i < count($a_urls); $i++){
yield new Request('GET', $a_urls[$i]);
}
};
// concurrency - максимальное число запросов, отправляемых асинхронно
$Pool = new Pool($Client, $Requests($Urls), [
'concurrency' => 125,
'fullfilled' => function(Response $response, $index){
/*Обработка успешного завершения запроса*/
echo($response->getBody());
echo($response->getStatusCode());
},
'rejected' => function(RequestException $reason, $index){
/*Обработка ошибок*/
echo($response->getStatusCode());
}
])
// Отправка всех запросов асинхронно
$Promise = $Pool->promise();
// Ожидание обработки всех запросов
$Promise->wait();
?>Примечание. В приведённом листинге создаётся пул запросов (объект класса Pool). Ему подаются на вход 3 параметра:
- объект класса Client (основной класс библиотеки, используемый для отправки запросов),
- анонимная функция (замыкание), генерирующая запросы (объекты класса Request),
- массив из трёх элементов (количество асинхронно отправляемых запросов, обработчик ответа при успешном запросе и обработчик ошибок).
Вызов метода promise() инициирует отправку запросов. Метод wait() используется для синхронизации запросов. После его вызова все запросы гарантированно будут обработаны.
Асинхронную модель поддерживают многие языки программирования (C++, C#, python, JavaScript и др.). Она также часто используется для создания UI (например, отрисовка прогресс бара при выполнении вычислений) или выполнения запросов к БД.
Программы, подобные моей, можно дополнительно ускорять, используя параллельное программирование: разбивать массив ссылок на части и обрабатывать их асинхронно в разных потоках.