/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Каждый день тысячи программистов трудятся не покладая рук. Они пишут код, контактируют между собой и, как и любой человек, совершают ошибки. Проблемы в коде могут повысить уровень рисков и стать критическими для компании. И с целью выявления таких ошибок специалисты проводят анализ кода.
В качестве испытуемого я выбрал модель стратегии по принятию решений, которая написана на языке программирования Python. Она прекрасно подходит на роль “белой мышки”, так как сама имеет несложный функционал, но располагает весьма значительным количеством строк кода.
Суть задачи состоит в поиске возможных проблем в кодовой части модели. Количество строк в коде довольно велико и исследовать такое вручную может занять не один рабочий день.
В этом случае на помощь приходит «Code Mining»!
«Code Mining» — это целое направление, которое фокусируется на анализе исходного кода и артефактов кода. Другими словами, «Code Mining» представляет собой анализ данных для разработки программного обеспечения.
В сравнении с ручным анализ «Code Mining» может:
- Осуществлять поиск различных проблем: от неправильных наименований переменных до логических ошибок;
- Указывать на проблемы с точностью до строчки;
- Обрабатывать большой объем программного кода;
- Выполнить анализ в короткий срок;
- Производить автоматический поиск уязвимостей без участия специалиста.
Итак, применим «Code Mining»! Для анализа кода будем использовать автоматизированные инструменты статистического анализа «flake8» и «pylint». Рассмотрим их подробнее.
Flake8
«Flake8» — это одна из самых популярных утилит для поисков проблем в Python, который объединяет в себе другие анализаторы кода «PyFlakes», «Pycodestyle», «Mccabe». Он обладает большим количеством проверок, а также прост в использовании и в настройке. Отчет «flake8» отображает предупреждения в объединенном выводе по каждому файлу в виде «Адрес файла – номер строки – номер ошибка — описание».
Утилита устанавливается с помощью одной команды: «pip install flake8»
Pylint
«Pylint» — это статистический анализатор кода для Python 2 или 3, который анализирует код, не запуская его. В отличии от многих других инструментов данная утилита объединяет в себе возможности стилистического и логического анализа кода. Он проверяет наличие ошибок, обеспечивает соблюдение стандарта кодирований и дает рекомендации по реорганизации кода. Это гибкий и мощный инструмент, который отличается большим количеством проверок и анализом кода.
Для установки утилиты требуется прописать в командной строке команду «pip install pylint» (на рисунке 2 продемонстрирована установка утилиты),
Проверим установку обоих инструментов командами «pylint —version» и «flake8 —version» (рисунок 3). Оба инструмента успешно установились и можно приступать непосредственно к анализу.
Сравнение
Начнем поиск уязвимостей с “flake8”. Данная утилита имеет довольно большое количество дополнительных плагинов для дополнительных проверок. Посмотреть список плагинов можно в репозитории «GitHub» под названием “awesome-flake8-extensions”. Установим интересующие нас плагины с помощью консольной команды «pip install <название плагина>»:
- flake8-bugbear – для поиска популярных логически ошибок
- flake8-coding – проверка комментариев
- naming – проверка наименований на соответствие международному соглашению по написанию кода «PEP8»
Теперь начнем непосредственный анализ используя команду «flake8». Введем в командную строку «flake8» для выполнения операции по всему каталогу модели. Если нужно указать конкретный скрипт, нужно добавить в конец команды путь к файлу, например, «flake8 main.py»
Для более подробного вывода, можно дописать дополнительные функции для утилиты: «flake8 –statistics –count», где «—statistics» это подсчет ошибок по категориям, а «—count» — их общие количество.
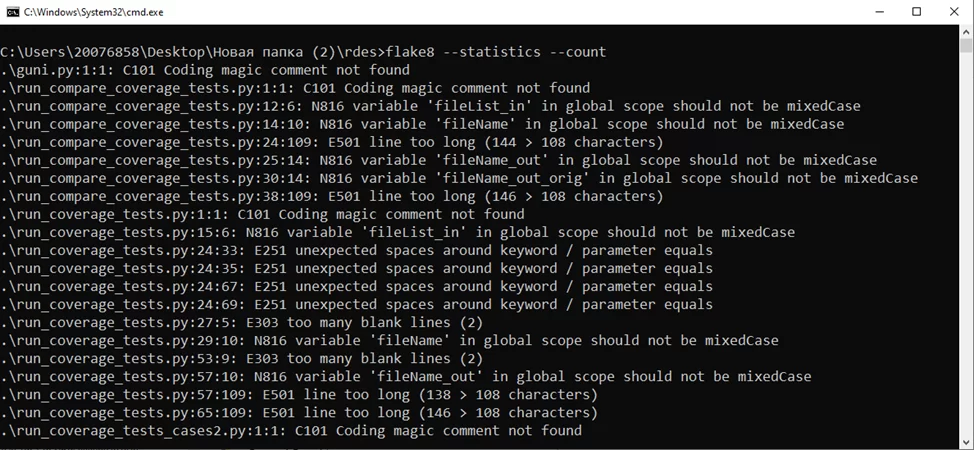
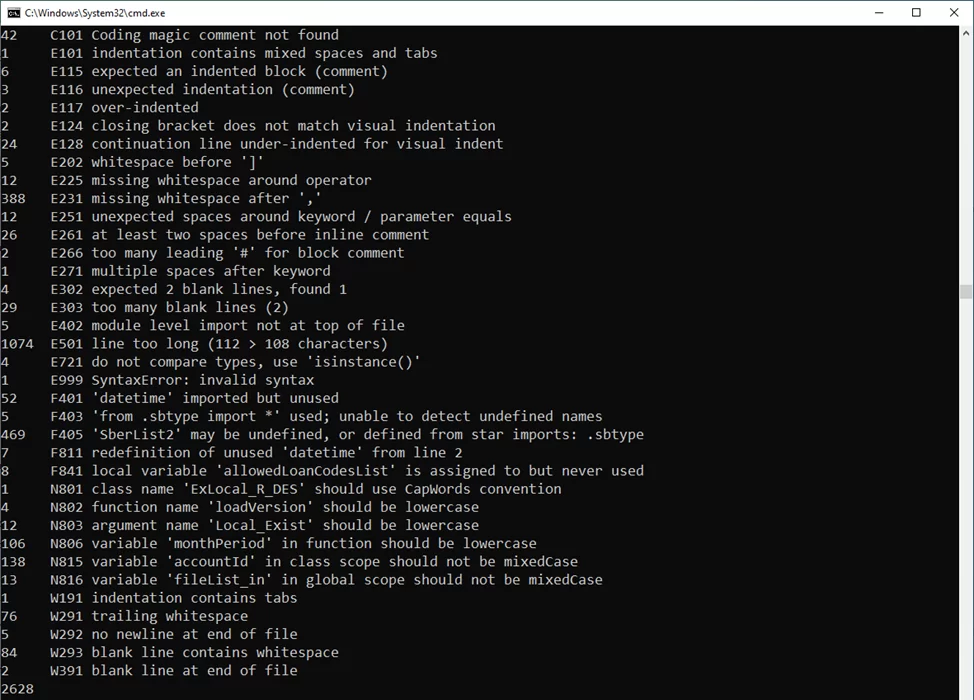
Как можно увидеть «flake8» нашел 2 628 ошибок и самыми популярными из них являются «E501: line to long» — слишком длинная строка и «F405: may be undefined, or defined from start imports» — необъявленная переменная.
В основном программа нашла синтаксические ошибки — не соответствие «PEP8» (PEP8 — Python Enhancement Proposal, предложения по развитию Python. Стандарты, которые позволяют создавать унифицированную проектную документацию для новых утвержденных возможностей языка Python. Самый известный PEP имеет восьмой порядковый номер. PEP8 содержит перечень принципов написания красивого и лаконичного программного кода на языке Python). Хоть они и не влияют на саму работу программы, но данные проблемы мешают другим программистам понимать код, что усложняет поддержку программного продукта.
Из-за того что вышеуказанный инструмент не сохраняет результаты работы в «json-файле» сохраним его в формате «.txt», просто добавив к концу прошлой команды «> result_flake8.txt».
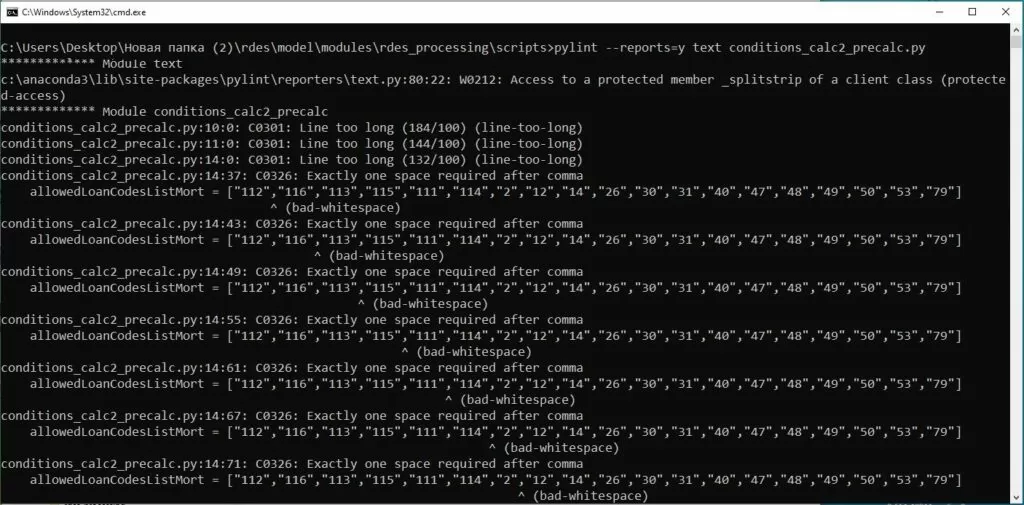
Теперь пришла очередь утилиты «pylint». Данный инструмент более мощный и продвинутый, чем его коллега. Он гораздо более строг и придирчив, содержит больше рекомендаций и правил. Но есть и недостаток — трудно проверить весь каталог модели, так как если в директории нет файла “__init__.py”, то проверять «pylint» его не будет. Для запуска работы анализатора, используется команда «pylint» и укажем ему файл для анализа.
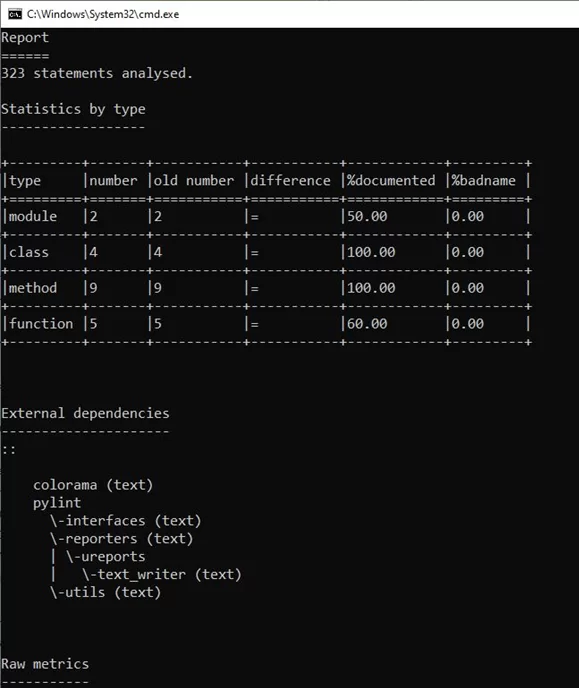
Для более подробного отчета, допишем команду: «pylint –reports=y text». Благодаря данным настройкам, «pylint» расширит отчет. Теперь помимо перечисления проблем, он показывает:
- Statistics by type – статистику по типу;
- External dependencies – внешние зависимости;
- Duplication – дублирование кода;
- Messegas by category – распределение ошибок по категориям
- % errors / warnings by module – процентное отношение ошибок
- Messages – количество одинаковых ошибок
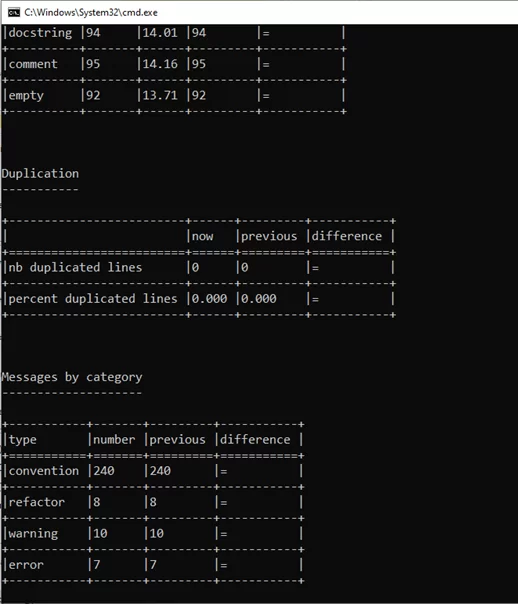
В итоге «pylint» обнаружил:
- 7 критичных ошибок (три “import-error /E0401”– неудачный импорт модулей, четыре “no-name-in-module/E0611”– имя не может быть найдено в модуле)
- 10 потенциальных ошибок (три “pointless-string-statement/W0105” – строковый оператор не имеет эффекта, семь “unused-import /W0661” – импортируемый модуль не используется)
- 8 ошибок, который требуют рефакторинга кода (“Too many branches/R0912”– функция или метод имеет много ветвей)
- 240 ошибок, которые нарушают правила соглашений и стилистику языка (самые популярные ошибки: “line-too-long /C0301” (82) – длина строки превышает заданное количество символов, и “ invalid-name /C0103” (43) – имя не соответствует правилам наименования)
Благодаря данным утилитам были найдены не только синтаксические ошибки, которые влияют на понимание и поддержку кода, но и ряд критических проблем, которые мешают модели нормально функционировать.
Что делать дальше?!
Все зависит уже от вашей цели:
- если вы проводили аудит кода, то занесите ошибки в отчет и отправьте его разработчикам на рефакторинг кода;
- если вы сам разработчик, то исправьте данные проблемы;
- если вы только «учитесь» и использовали инструменты для проверки себя и своего кода, то проанализируйте выявленные проблемы и попытайтесь не допускать их вновь.
Качество вашего кода поднимется на новый уровень!