/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Потенциально, GPU обладают огромной производительностью, благодаря возможности выполнять большое количество задач параллельно.
Для подтверждения своих слов, об огромной производительности GPU по сравнению с CPU, приведу график роста вычислительной способности этих двух типов процессоров во времени:
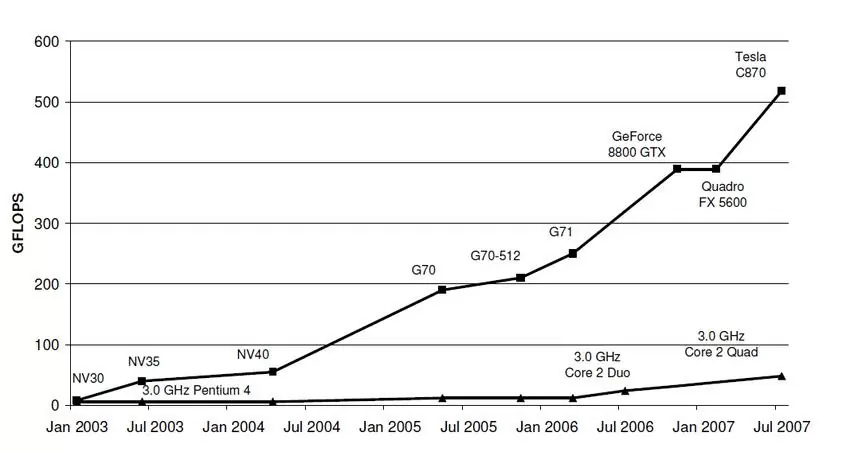
Производительность графических процессоров растет семимильными шагами. Текущие графические процессоры могут запускать десятки тысяч потоков выполнения, которые позволяют более эффективно выполнять параллельные задачи.
Компания Nvidia разработала свою проприетарную технологию CUDA, которая позволяет использовать графические процессоры для решения множества прикладных задач из совершенно разных областей. Для начала посмотрим в чем разница архитектур CPU и GPU, а также почему GPU удается выполнять некоторые задачи во много раз быстрее.
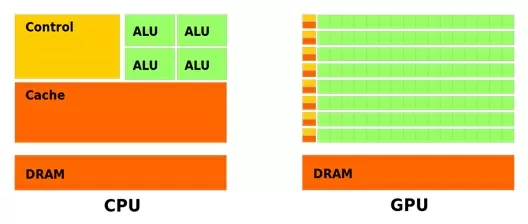
Как мы видим, при сравнении этих устройств, GPU обладает большим количеством ALU, которые разделяются на сектора или блоки, у каждого из которых есть свой контроллер и свой кэш 1-го уровня. Именно поэтому GPU позволяет не просто запустить несколько потоков, но и обеспечить массовый параллелизм, что, конечно, должно дать существенный прирост в задачах, выполняемых параллельно.
Посмотрим насколько вычисления с использованием CUDA быстрее в сравнение с обычным выполнением на CPU.Замеры времени работы на GPU учитывают время передачи информации с хоста на девайс. Нельзя не учитывать этот факт, так как это является слабым местом из-за небольшой пропускной способности шины PCI-express и отсутствия многоуровневого кэша.
Вооружимся следующим технологическим стеком: python, numpy, cupy, pycuda. Характеристики тестового стенда:
- CPU Ryzen 2700 3.6Ghz 8-cores
- GPU Nvidia GTX 1060 3G
Для начала посмотрим, как вычисления с CUDA помогают в задачах линейной алгебры, а именно в матричных умножениях.
Для реализации использовались пакеты numpy (CPU), pycuda (GPU) + custom kernel реализованный на С++
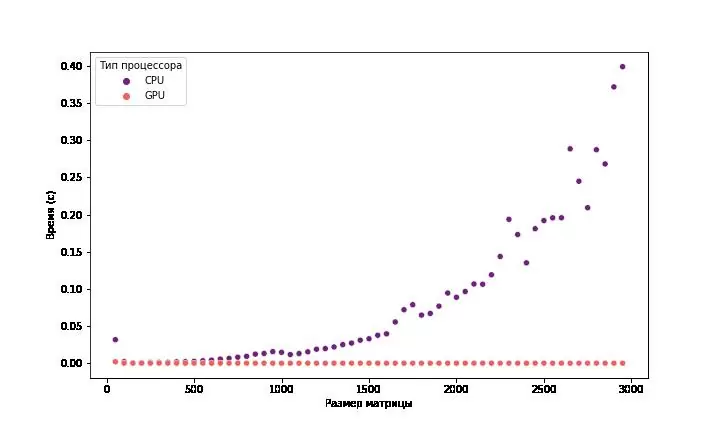
Как видно из графиков при возрастании размерности матрицы, достаточно быстро показывает свою эффективность большое количество потоков выполнения, которые мы можем запустить на графическом процессоре. Максимальное ускорение составило ~2000x. Но не все задачи так прекрасно распараллеливаются как умножение матриц.
Рассмотрим следующую задачу, в которой мы будем строить спектрограмму музыкальной композиции с помощью быстрого преобразования Фурье. Эта задача решается на локальной машине. Используются библиотеки Librosa (CPU ) и DALI (CUDA cuFFT).
Спектограмма на Librosa
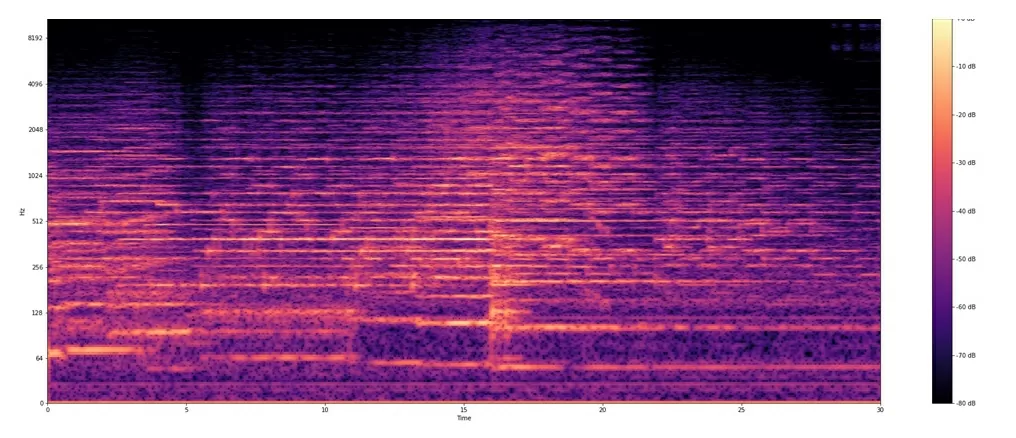
Спектрограмма на Dali
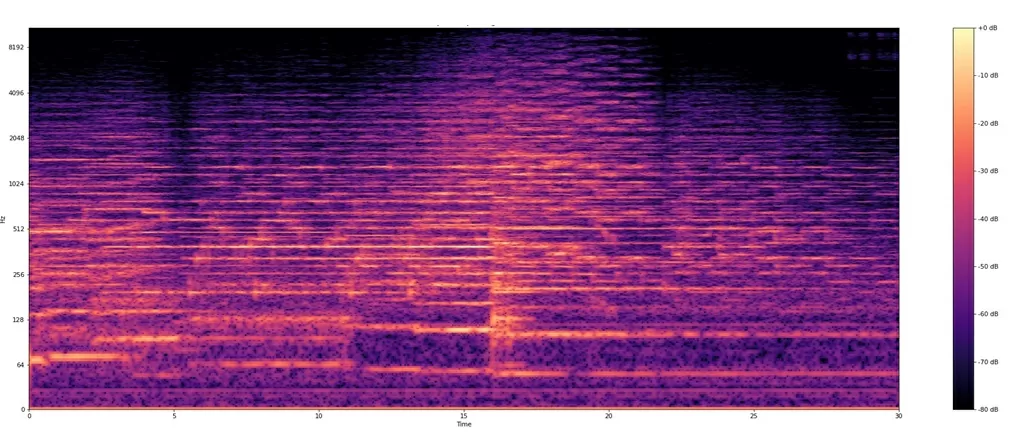
Средняя ошибка вычислений составляет всего 0.00047db, что является отличным результатом. Скорость выполнения быстрого преобразования Фурье удалось увеличить в 5 раз с использованием технологии CUDA.
Ну и напоследок будем вычислять число Пи методом Монте-Карло.
Используемые пакеты: numpy(CPU), cupy(GPU)
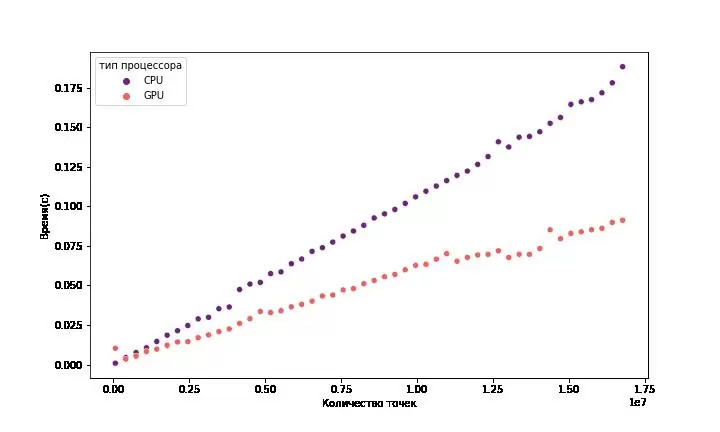
На данном графике видно заметное улучшение в производительности с возрастанием количества генерируемых точек.
Однако, при слишком большом количестве точек, вы можете наткнуться на ошибку CudaMemAlloc и тут нужно уже как-то разбивать данные и обрабатывать по частям, что может сказаться негативно на результатах, т.к. передача данных через шину PCI является слабым местом этой технологии.
В заключение хотел бы сказать, когда стоит использовать вычисления на графическом процессоре:
- Ваша задача хорошо параллелится;
- Ваши данные можно целиком поместить в память видеокарты;
Когда не стоит использовать графический процессор:
- Ваша задача требует сложных операций где важнее тактовая частота;
- Вам требуется низкая задержка;
- Вашу задачу сложно хорошо распараллелить.