/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
EmptyDataError… Звучит знакомо? В этой статье рассмотрим несколько советов, дабы избежать ошибок при загрузке файлов CSV с помощью Pandas DataFrame.
Данные находятся в центре конвейера машинного обучения. Чтобы использовать полную мощность алгоритма, данные должны быть сначала правильно очищены и обработаны.
Первый шаг очистки/обработки данных — загрузка файла и последующее установление соединения по пути к файлу. Существуют файлы с различными типами разделителей:
- разделители-табуляция;
- разделители-запятые;
- разделители из нескольких символов и другие.
Импорт файла в фрейм данных Pandas часто вызывает ошибки. Например, EmptyDataError говорит о том, что нет столбцов для синтаксического анализа из файла. Возникает ошибка в основном из-за того, что:
- неверно указан путь к файлу;
- неверно указаны типы разделителей данных;
- неверно указан каталог файлов;
- файловое соединение не установлено.
Специалисты по обработке данных не могут позволить себе тратить много времени на трудоемкий этап. Поэтому при загрузке файла необходимо выполнять определенные шаги, которые позволят сэкономить время и избавят от хлопот, связанных с просмотром большого количества информации, чтобы найти решение вашей конкретной проблемы.
Чтение и импорт файла CSV не так прост, как можно предположить. Вот несколько советов, которые помогут загрузить файл данных для построения модели машинного обучения.
- Проверьте свой тип разделения в настройках.
Для Windows
- Зайдите в Панель управления;
- Нажмите на региональные и языковые параметры;
- Перейдите на вкладку «Региональные параметры»;
- Нажмите Настроить/Дополнительные настройки;
- Введите запятую в поле «Разделитель списка» (,);
- Дважды нажмите «ОК», чтобы подтвердить изменение.
Примечание: работает, только если «десятичный символ» также не является запятой.
Для MacOS
- Зайдите в Системные настройки;
- Щелкните «Язык и регион», а затем перейдите к параметру «Дополнительно»;
- Измените «Десятичный разделитель» на один из следующих сценариев: если десятичным разделителем является точка, то разделителем CSV будет запятая, если десятичным разделителем является запятая, то разделителем CSV будет точка с запятой.
2. Воспользуйтесь предварительным просмотром данных (в блокноте Jupyter, либо в Microsoft Excel) для проверки способа разделения данных.
3. Правильно укажите все аргументы.
От правильности заполнения аргументов функции pd.read_csv напрямую зависит правильность чтения вашего CSV файла. Рассмотрим список всех аргументов:
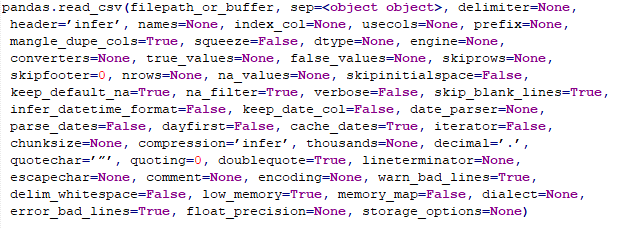
Нас больше всего интересует следующий аргумент: sep — определяет тип разделения между значениями данных. По умолчанию ‘,’. Наиболее распространенные типы разделителей: запятая, табуляция и двоеточие. Следовательно, они должны быть указаны, как sep = ‘,’, sep = », sep = ‘;’ соответственно. Это сообщит pandas DataFrame, как распределять данные по столбцам.
Если после корректного указания аргументов проблема не устранена, воспользуемся следующим пунктом.
4. Проверьте путь к файлу.
Местоположение файла должно быть указано правильно. Чаще всего люди не знают рабочий каталог и в конечном итоге указывают неправильный путь к файлу. В этом случае мы должны проверить рабочий каталог, чтобы убедиться, что указанный путь к файлу написан правильно. Напишите приведенный ниже код, чтобы проверить рабочий каталог.
pwd # to check directory
‘/Users/syedwaqar/Huma’
Мы также можем изменить рабочий каталог, используя приведенную ниже строку кода. После указания нового каталога мы должны указать путь.
cd/Users/syedwaqar
/Users/syedwaqar
5. Отметьте разделитель, используемый для указания местоположения файла.
Часто ошибка возникает и при изменении рабочего каталога. Это происходит из-за того, что разделитель не написан в соответствии с правильным синтаксисом.

Прежде всего проверьте разделитель, используя команду ниже.
os.sep # to check the separator used for specifying the file location
‘/’
Затем используйте разделитель только в начале расположения каталога, а не в конце. Пожалуйста, обратите внимание, что эта спецификация синтаксиса разделителя (/) верна для MacOS и может быть неверна для Windows.
cd/Users/syedwaqar
/Users/syedwaqar
Если ваш файл находится в рабочем каталоге, упомяните только имя файла, как показано ниже.
path = ‘healthcare-dataset-stroke-data.csv’
con = sq3.Connection(path)
Но если ваш файл находится в какой-либо другой папке, вы можете указать следующие папки после рабочего каталога, например, ваш рабочий каталог — «/Users/username», а ваш файл находится в папке с именем «files» в «документах», тогда используйте следующий код:
path = 'Documents/files/filename.csv'6. Убедитесь, что файл находится по пути:
Теперь проверьте, присутствует ли ваш файл по описанному пути, используя приведенный ниже код. Мы получим ответ либо «True», либо «False».
path = ‘healthcare-dataset-stroke-data.csv’
con = sq3.Connection(path)
os.path.isfile(‘healthcare-dataset-stroke-data.csv’)
True
Con
<sqlite3.Connection at 0x11f288e40>
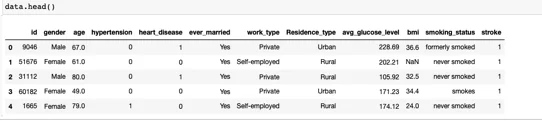
7. Распечатайте данные файла для перекрестной проверки:
Теперь мы можем проверить, правильно ли загружен наш файл данных, используя приведенный ниже код.
data.head ()
Эти советы помогут вам больше не сталкиваться с проблемами при загрузке файла CSV с помощью Pandas DataFrame.