/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В данной статье приведено описание системы управления базами данных (СУБД) Teradata через призму сравнения с аналогичными, известными и более распространенными решениями:
— MS SQL – Ориентированно на исполнение запросов на одном физическом сервере;
— Oracle – Ориентированно на исполнение запросов на одном физическом сервере;
— Hadoop – Ориентировано на распределённом хранении данных.
Представим ситуацию, когда потребителю нужна высокопроизводительная, отказоустойчивая, масштабируемая СУБД.
Как бы ни были хороши и привычны MS SQL и ORACLE, но мы ограниченны одним сервером. В какой-то момент мы столкнёмся с проблемой ограничения по производительности.
Hadoop действительно лишена недостатка, в ограничении использования одного сервера. Позволяет, использовать разнородное оборудование, размещенное в больших сетях, а стоимость хранения данных невелика. Его слабость заключается в использовании TCP/IP v4/v6 протоколов между критичными узлами Hadoop, что снижает производительность обмена информацией в сети.
СУБД Teradata для связи физических серверов (Нод[1]) использует специализированную физическую сеть BYNET, которая, при передаче данных, обладает низкими накладными расходами, обеспечивает недоступную для конкурентов производительность и время доступа. Если учесть, что скорость сети является самым узким местом в распределенных СУБД, то и наличие BYNET является серьёзным преимуществом. Связанно это с тем, что не все запросы хорошо распараллеливаются и грубые методы «FULLSCAN» нагружают именно связку между Нодами.
SMP узел – это физический сервер на котором инициировано
несколько экземпляров PE (Parsing Engine) и AMP (Access
Module Processor)
представлен на рисунке:
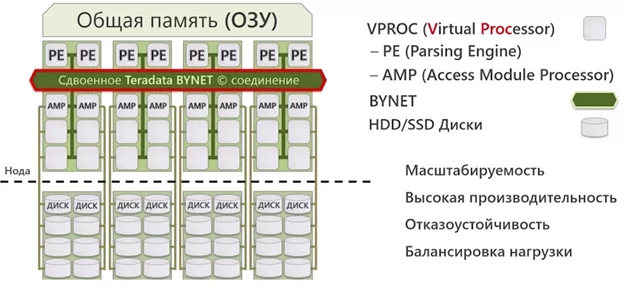
Хранилище данных Teradata представляет собой связку из Жестких дисков и SSD накопителей, что даёт наилучшие показатели времени доступа к данным из хранилищ, использующих Жесткие диски.
При организации СУБД Teradata под каждый определенный объем дискового пространства назначается виртуальный процессор «AMP» (Access Module Processor) и «PE» (Parsing Engine). Их работа практически не зависит от других виртуальных процессоров.
Если сравнивать с точки зрения систем хранения данных, то в ORACLE, MS SQL, Hadoop жесткие диски подключают через высокопроизводительные дисковые контроллеры сторонних производителей, а в Teradata используются специализированные хранилища, которые в свою очередь лучше интегрированы в систему.
Указанная концепция хранения позволяет использовать такое понятие, как «температура данных». Данная технология является серьёзным конкурентным преимуществом так как в Teradata данные распределяются в зависимости от их востребованности на более быстрых секторах (цилиндрах) жесткого диска или наоборот.
В связи с тем, что подключение к хранилищу происходит на более низком уровне, чем у конкурентов, АМП выполняет агрегацию, создаёт блокировки, осуществляет вставку, чтение и удаление значительно эффективней. То есть между потребителем и самими данными меньше узлов и издержек.
Благодаря унифицированной структуре размещения блоков данных на хранилищах Teradata, подключая новые Ноды к существующему кластеру, мы получаем увеличение производительности, отказоустойчивости, доступного дискового пространства. Аналогично при отключении узлов кластера мы получаем снижение всех указанных характеристик.
Подключение, новых Нод, происходит проще чем на Hadoop. Перенос данных осуществляется быстрее, как и балансировка нагрузки.
Главным недостатком СУБД Teradata, относительно конкурентов, является высокая стоимость, как системы в целом, так и стоимость хранения данных.
Второй недостаток — скудный инструментарий по работе с СУБД.
Третьим недостатком является тот факт, что Teradata получила меньшее распространение чем Hadoop. Из этого исходят и проблемы, с внедрением и сопровождением данной СУБД.
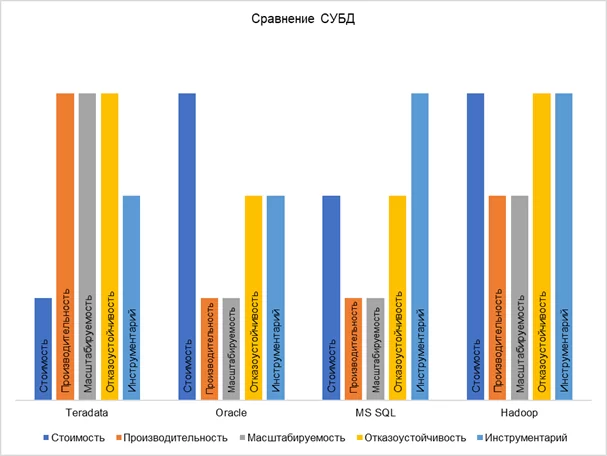
Подведем итог визуализацией сильных и слабых сторон СУБД Teradata по отношению к конкурентам:
[1] Node. Это отдельное вычислительное устройство (компьютер), являющийся частью группы таковых устройств (кластера) которые совместно используются для решения вычислительных задач.