/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
Про подготовку:
Начать разработку решили с создания модели классификации для поиска оценочных суждений и фактуры, потому как это была самая нетривиальная задача из всего списка. Просто пройтись регулярными выражениями по текстам актов – это совсем не гарантия найти большую часть предложений с оценочными суждениями и фактурой, такой подход не гарантирует и высокую долю ложно положительных ошибок: классификация нейтральных предложений, как оценка или факты, потому что никак не учитывается контекст. Разработка дополнительных функций проверки изначально в задачу мы не закладывали, они родились уже в процессе работы над основной задачей.
Для того, чтобы обучить модель, нужны данные. Для нашей задачи на разметку пошло примерно 1000 актов.
Для определения, что мы хотим выделять в актах коллеги разработали специальный интерфейс для разметки, в котором можно было проставлять метки предложениям. Было выбрано три категории: фактура, оценочное суждение и, так называемое, другое (это как раз то, что не сильно интересно нашим клиентам), набор классов для каждой задачи может варьироваться. В базе данных сохранили информацию о проставленной категории, которую получили при разметке.
Разметку проводили, основываясь на мнении экспертных аудиторов, которые погружены в специфику и непосредственно работают с актами, знают тонкости.
Стандартный preprocessing pipeline:
Для обучения модели необходимо провести предобработку данных: очистить от часто встречающихся слов, которые не несут в себе смысла (предлоги, частицы, междометия), заменить персональные данные, названия организации и числа масками.
Чтобы найти имена использовали две предобученные нейросети natasha и NER (от DeepPavlov), найденные имена заменяли на маску – ФИО, чтобы не терять признаки для определения фактуры. Важно заметить, что, если подавать инструментам текст нижнего регистра, имена не будут найдены. Такая особенность обусловлена данными, на которых тренировали нейросети – в основном это были тексты новостных лент, где регистр сохранялся. Поэтому все слова в предложениях, которые подаются на вход, необходимо написать с заглавной буквы. Такая возможность предусмотрена в библиотеке string на python. Номера договоров и числа искали при помощи регулярных выражений и заменяли на соответствующие маски. У инструмента есть ограничение: если в предложении больше 512 символов, то оно не обработается, выпадет ошибка, отдельно мы дописали «умную нарезку», чтобы слова не разрывались в предложениях посередине. Ниже представлены функции для извлечений имен, локаций и организаций.
def fio_extractor(text_string):
"""
fio finder and extractor in format A.A. Ivanov, A A Ivanov
Using tags I-LOC, B-LOC, I-ORG, B-ORG it is possible to detect
locations and organizations
returns: [‘A’, ‘.’, ‘A’, ‘.’, ‘Ivanov’]
"""
token, tags = ner([string.capwords(text_string)])
i_per = [i for i, x in enumerate(tags[0]) if x == 'I-PER']
b_per = [i for i, x in enumerate(tags[0]) if x == 'B-PER']
per = sorted(i_per + b_per)
fio = [token[0][f] for f in per]
return fio
Очистку предложений от «мусорных» слов сделали при помощи русских стоп-слов из библиотеки nltk, а также сделали словарь по частоте встречаемости разных слов в обучающей выборке, где ключами были слова, а значениями – количество раз, сколько конкретное слово встретилось в выборке, и удалили самые частые и бесполезные.
from deeppavlov.models.tokenizers.ru_tokenizer import RussianTokenizer
ru_stops=set(stopwords.words('russian'))
from nltk.corpus import stopwords
rus_tok = RussianTokenizer(stopwords = final_stops, lemmas = True, alphas_only = True)
Почему мы выбрали DeepPavlov, а не Natasha?
Легко ли найти конец предложения? Вопрос кажется глупым, но на самом деле для машины эта задача оказывается не такой уж и тривиальной. Простое разделение по точке даст множество ошибок в делении текста на предложения, «спотыкаясь» о множество сокращений совершенно разных типов: руб., г., Иванова А.А. и прочие.
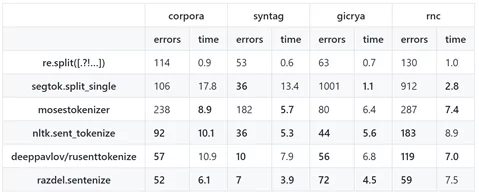
Тем не менее задача не новая для обработки естественного языка, поэтому можно использовать предобученные нейросети для ее решения. Параметры, на которые стоит обратить внимание при выборе фреймворка – локализация и гибкость настройки. Так, мировое сообщество представило целый набор моделей для токенизации связных текстов на предложения, но они не подходят для токенизации русского текста.
Самые популярные фреймворки для работы с русскими текстами – это rusenttokenize от DeepPavlov и razdel от Natasha.
Обе сети тренировали на открытых текстах, основу которых составляли новостные ленты. И несмотря на то, что на открытых корпусах Natasha демонстрирует результаты лучше, на наших текстах одно предложение, выделенное Natash-ей могло соответствовать трем от DeepPavlov:
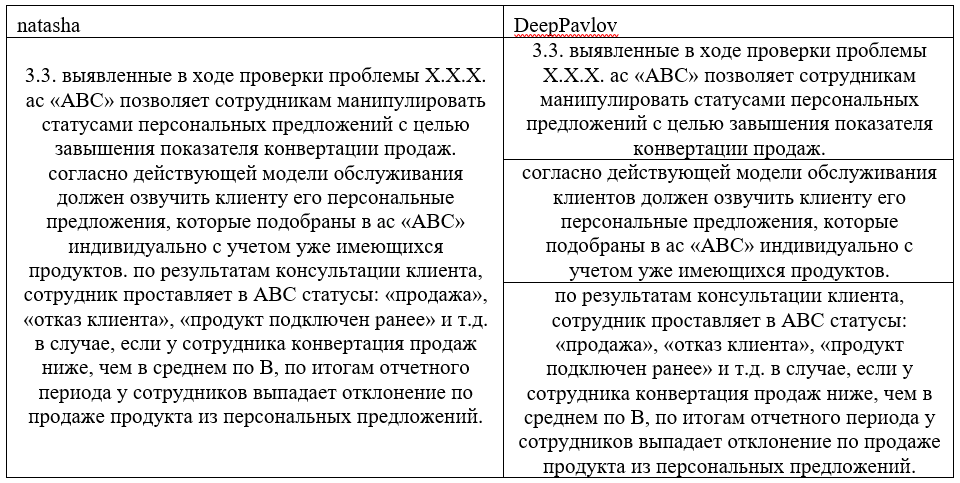
После ряда своих тестов, мы выбрали токенизатор от DeepPavlov. При настройке инструмента можно указать целый ряд кастомных параметров (чего нельзя сделать в razdel.natasha):
- Сокращения, которые не стоит воспринимать как конец предложения
- Сокращения, которые стоит читать как одно слово
- Аббревиатуры
Удалось даже добавить сокращения, которые не используются в стандартном решении, исходя из специфики текстов, с которыми мы работали.
from rusenttokenize import ru_sent_tokenize
from deeppavlov.models.tokenizers.ru_tokenizer import RussianTokenizer
def sentence_collection(text_without_tables):
""" after clear text (without tables) extractions sentence collection"""
shortenings_ = {'зав', 'куб', 'о', 'тыс', 'мин', 'букв', 'обл', 'сек',
'русск', 'зам', 'коп', 'повел', 'яз', 'прим','гос', ... ‘оао’}
paired_shortenings_={('т', 'п'), ('т', 'е'), ('у', 'е'), ('н', 'э'), ('и', 'о'), ('т','к'),('т','д'), ('т','ч')}
sentences = []
for sentence in text_without_tables:
sentences.append(ru_sent_tokenize(sentence,
shortenings = shortenings_,
joining_shortenings={},
paired_shortenings=paired_shortenings_))
sentences=[j for i in sentences for j in i]
sentences = [i for i in sentences if len(i)>0]
return sentences
Коротко о модели и метрике:
С самого начала было понятно, что придется столкнуться с дисбалансом, поэтому мы выбрали для работы CatBoost, так как модель умеет учитывать разные веса для классов, быстро обучается при использовании GPU и показывает самые высокие результаты при сравнении с бенчмарками.
from sklearn.utils import class_weight
class_weight = class_weight.compute_class_weight('balanced', np.unique(y_train), y_train)
model = CatBoostClassifier(class_weights=class_weight,
use_best_model=True,
task_type="GPU",
eval_metric='F1',
loss_function = 'MultiClass')
Крайне важно в задачах классификации выбрать верную метрику, которая будет действительно описывать качество работы модели. В нашем случае был сильный дисбаланс – 40% обучающей выборки составил класс «другое», и этот доминирующий класс не являлся целевым. Важно понимать, что метрики Accuracy и ROC-AUC и обобщенная F1 (взвешенная и усредненная) будут завышены в сторону не целевого класса, так как опираются на качество верной идентификации этого класса в том числе.
Почему это плохо: когда мы выводим модель в промышленную среду, мы будем получать на вход предложения из всего акта, там будет еще больше предложений класса «другое», которых при обучении мы на вход не подавали. Модель должна научиться выделять целевые классы и относить все что не получилось к оставшемуся нецелевому классу. Когда она встретит предложения из слов, которые она никогда не «видела» при обучении, ее логичным поведением будет отнести его к не целевому классу. Поэтому, когда тренировали модель, мы следили за показателем F1 по целевым классам. Посмотреть этот параметр по классам можно, указав параметр “none” при выборе типа усреднения метрики при инициализации.
from sklearn.metrics import f1_score
f1_score(list(y_test), y_predicted, average = None)
Мы тренировали несколько моделей как на бинарную классификацию, так и на мультиклассовую, везде учитывая параметр class_weights при инициализации CatBoost, что позволило достичь приемлемого уровня качества классификации по целевым классам в сравнении с алгоритмами LightGBM и sklearn GradientBoosting.
Модель – это хорошо, но как использовать полученные выводы?
Модель натренировали, результаты получили, но как теперь передать их аудиторам? Настало время инженерной части.
«В бою» на вход модель будет получать акт целиком. Акт – это документ сплошного текста разного форматирования с множеством таблиц. Чтобы работать с текстом Word не обязательно уметь писать на C# и пользоваться платными библиотеками, а также не нужно лезть в XML – структуру документа. Python сообщество написало одноименную библиотеку-обертку для работы с docx файлами, в ней реализовано множество функций, которые если не полностью, то уж точно по большей части способны покрыть потребности разработки. С ее помощью мы отделили табличный текст от связного, решили анализировать его отдельно.
def text_without_tables(document):
"""
Text extraction escaping table text
"""
text_without_tables = []
for para in document.paragraphs:
text_without_tables.append(para.text)
text_without_tables=[i for i in text_without_tables if len(i)>0]
text_without_tables =[i.replace('\t','') for i in text_without_tables]
return text_without_tables
Связный текст при помощи библиотеки docx получили разбитым на абзацы. Каждый абзац при помощи DeepPavlov разделили на предложения. Далее мы поделили предложения на токены, привели слова в начальную форму и подали в классификатор на деление по классам. Результатом классификатора явилась метка класса – список цифр. Отдавать аудитору разрезанный по предложениям акт в таблице с метками классов не user friendly подход, и тут мы нырнули в docx снова.
В структуре документа есть разные теги, самый близкий тег, который может содержать в себе предложение – run. Один абзац состоит из нескольких run-ов. Как правило, run – это текст единого форматирования, но на практике мы увидели, что из run-ов предложения собрать не получится, некоторые из них содержат лишние части, некоторые оборваны. Тогда мы обратились к тегу paragraph, извлекли оттуда все предложения, разбили их своим токенизатором и «пересобрали» параграф из run-ов, которые соответствовали предложениям.
Теперь мы получили возможность выделять цветом и оставлять комментарии к тем предложениям, которые нам нужны, а не их кускам или целым параграфам.
import docx
from docx.api import Document
document = Document(path)
def replace_runs(document):
"""
Replaces <run> tags in document with custom sentences saving its style and formatting
"""
for p in document.paragraphs:
number_of_runs = len(p.runs)
text=[]
text.append(p.text)
run_sentences = sentence_collection(text)
if len(run_sentences)!=number_of_runs:
last_run = 0
for r in range(len(run_sentences)):
p.runs[r].text = run_sentences[r]
last_run = r+1
for rep in range(last_run, number_of_runs):
p.runs[rep].text = ''
return document
Получив такую возможность, мы смогли подсветить в тексте предложения, содержащие оценочные суждения и фактуру, чтобы автор мог повторно обратить на них внимание и переформулировать свои мысли.
П-ссс, допфичи есть? А если найдем?
С того момента, как мы обучили классификатор, а затем получили большую область контроля над итоговым выводом, фантазия нашего внутреннего заказчика получила второе дыхание. И это очень даже неплохо, потому что разработка не сталкивается с подобными узкопрофильными задачами в своей работе, сложно понять, чем еще можно помочь аудиторам при составлении актов. В дополнение к созданному функционалу мы доработали еще несколько удобных фишек. Люди, которые часто пишут отчеты, склонны использовать канцеляризмы в своих работах: нагруженные сложные предложения просто невозможно интерпретировать третьим лицам, крайне трудно понять, что хотел донести автор. Мы начали искать такие предложения, чтобы авторы старались их избегать. С помощью библиотеки natasha мы получили доступ к структуре предложений и смогли анализировать связи между словами, припомнив школьные правила о том, что такое сложносочиненное и сложноподчиненное предложение, добавили условия к анализу связей и получили вполне логичный поиск.
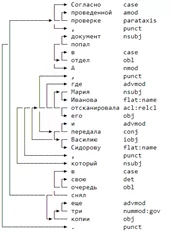
Визуализация связей в предложении, natasha
К найденным предложениям в итоговом отчете мы прикрепляли комментарий, в тексте которого указывали, что стоит переписать предложение попроще. Мы использовали
natasha == 0.10.0 и совместимые с ней razdel, navec, slovnet
from ipymarkup import show_dep_ascii_markup as show_markup
from razdel import sentenize, tokenize
from navec import Navec
from slovnet import Syntax
import re
navec = Navec.load('navec_news_v1_1B_250K_300d_100q.tar')
syntax = Syntax.load('slovnet_syntax_news_v1.tar')
compound_unions = {'а', 'но','как', 'где','либо', 'почему', 'тоже', 'также', 'или', 'когда', 'как будто', 'что', 'чтобы',
'потому что','бы', 'так как', 'если', 'какой', 'чей', 'какая', 'чья', 'чье', 'чьё', 'который', 'которая','которые'
'которых','которого',"которой", 'которыми','которой','которым', 'которыми','которой','которому',
}
def compound_sentences_detection(sample):
cs = []
sample_sentence = ' '.join(re.sub(r'[^а-яА-Я ]', ' ', sample).split())
chunk = []
for sent in sentenize(sample_sentence):
tokens = [_.text for _ in tokenize(sent.text)]
chunk.append(tokens)
syntax.navec(navec)
markup = next(syntax.map(chunk))
words, deps = [], []
for token in markup.tokens:
words.append(token.text)
source = int(token.head_id) - 1
target = int(token.id) - 1
if source > 0 and source != target: # skip root, loops
deps.append([source, target, token.rel])
roles = []
for i in deps:
role_rel = i[-1]
roles.append(role_rel)
if words.count('что')!=0 or words.count('который')!=0 or words.count('которая')!=0 or words.count('которых')!=0 or words.count('которого')!=0 or words.count('которой')!=0 or words.count('которым')!=0 or words.count('которыми')!=0 or words.count('которой')!=0 or words.count('которому')!=0:
if roles.count('nsubj')>2 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
elif roles.count('nsubj')>2 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
elif roles.count('nsubj')>2 & roles.count('nsubj:pass')>1 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
elif roles.count('acl:relcl')>0 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
else:
if roles.count('nsubj')>1 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
elif roles.count('nsubj')>1 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
elif roles.count('nsubj')>1 & roles.count('nsubj:pass')>1 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
elif roles.count('acl:relcl')>0 & len(set(words).intersection(compound_unions))>0:
print(sample+'\n')
cs.append(sample)
return cs
Если коротко описать код словами, то мы искали несколько подлежащих и учитывали наличие союзов и союзных слов в предложениях.
Также выяснилось, что аудиторы часто забывают упомянуть тип риска, указать кому адресованы рекомендации, сроки их реализации, дублируют причины нарушения очень общими словами и не верно оформляют таблицы регуляторных и информационных рисков. Все эти вещи мы тоже добавили в формирование итогового документа, использовав инструменты простого поиска по тексту и немного простых ds-алгоритмов и библиотек DeepPavlov + natasha.
Что мы получили от этой задачи:
Вклад проекта в общий уровень развития команды можно оценить с двух сторон: приобретенные hard skills & soft skills.
Hard skills: знакомство с локальными фреймворками для обработки естественного языка — это не выполнение абстрактных проектов из сети на английском языке, особенности которого повторить на русском пока невозможно, а решение реальных задач. Работа с документацией и поиск возможностей для нестандартного ее использования (как это вышло со сложными предложениями, ведь по сути, использоваться инструмент должен был для задач name entity recognition). Осознанный выбор метрики и тюнинг моделей: мы начали с RNN для обработки последовательного текста, но в итоге дошли до CatBoost по ряду показателей, смогли учесть дисбаланс классов в выборке, чем подняли качество классификации.
Soft skills: Все. Абсолютно все учились работать в команде, договариваться, слушать друг друга, искать компромиссы, придумывать что-то новое и перенимать опыт коллег. Мы не раз сталкивались с тем, что у разработки мнение противоречило точке зрения заказчиков, но это рабочий процесс, в итоге мы всегда находили компромисс и формировали общее видение проекта для команды.