/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 2 мин.
Одним из простых способов обезличивания данных может быть использование языка Python. Работать можно с файлами в любом формате, как в текстовом (.csv), так и в формате .xlsx. Мы будем использовать модуль pandas для удобства обработки.
import pandas as pd
data = pd.read_excel('Информация.xlsx')Загружаем данные в DataFrame, и определяем с какими данными будем работать.
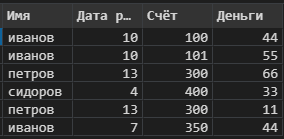
Есть два основных подхода к обфускации данных:
— Замена данных уникальным ключом. Это позволяет гарантировать на 100% невозможность восстановления исходной информации, если у нас нет таблицы соответствия ключ-данные,
— Кодирование. В этом случае мы используем специальные функции для того, чтобы сформировать однозначное соответствие между данными и выходным значением, например, хэширование. Хэширование позволяет в дальнейшем сравнивать между собой разные наборы данных, используя хэши. Однако риск восстановления информации из хэша есть, хоть и минимальный.
Рассмотрим вариант с формированием ID записи. Для этого мы будем использовать ранжирование записей по группе.
data['id'] = data[['Имя', 'Дата рождения']].\
apply(tuple, axis = 1).\
rank(method = 'dense')Формируем группы из необходимых столбцов, и применяем к ним функцию ранжирования. Получаем новый столбец, который содержит ID, уникально идентифицирующий клиента:
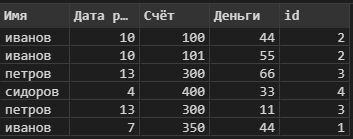
Рис. 2 Данные с уникальным столбцом-идентификатором клиента
Теперь рассмотрим пример получения хэша для номера счёта. Импортируем библиотеку hashlib, и с её помощью формируем хэш для каждой из строк
import hashlib
data['hash'] = data['Счёт'].\
apply(lambda x: hashlib.md5(str(x).encode('utf-8')).hexdigest())По полученному результату видно, что для одинаковых счетов мы получаем одинаковые хэши.
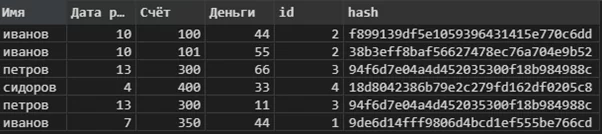
Таким образом мы можем получить файл, в котором все личные данные клиента скрыты, тем самым гарантируя анонимность при дальнейшей работе с ними. Это крайне актуально в случае, например, удалённой работы.