/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
RSS (Rich Site Summary) — семейство форматов XML для описания новостных каналов, статей, изменений блогов и т.д. Данная технология экономит время и помогает получить необходимую информацию, как только она будет размещена на сайте.
В данной статье, мы разберем как написать свой RSS-агрегатор.
Давайте выясним, что такое RSS технически. Изнутри этот файл включает три структуры блоков:
- Метаданные – заголовки, подзаголовки, изображения, описания, основной текст.
- Гиперссылки — для чтения полной версии новостей
- Категории статей и другие дополнительны метаданные
Принцип использования RSS-канала можно представить как беглое знакомство с оглавлением книги или просмотр газетных заголовков. Теперь информацию с сайта можно предоставить в двух видах — полная версия статьи или название с объявлением.
Для начала предлагаем разобраться в фрагменте объекта исследования.
<rss xmlns:news="/" version="2.0">
<channel>
<title>Сейчас.ру</title>
<description>Сейчас.ру</description>
<link>/</link>
<image>
<link>"/"</link>
<url>/images/logo100.gif</url>
<title>Сейчас.ру</title>
</image>
<item>
<title>
ЦИК: возможно проведение досрочного голосования по Конституции на протяжении недели
</title>
<description>
<![CDATA[
Окончательное решение по каждому региону будут принимать избирательные комиссии на местах
]]>
</description>
<pubDate>Fri, 20 Mar 2020 17:41:46 +0300</pubDate>
<link>/state/15616</link>
<category>NEWS</category>
<author>Карина Мелова</author>
<guid isPermaLink="true">/state/15616</guid>
</item>
<item>
<title>
На дорогах Подмосковья устанавливается ограничение скорости 50 км/ч
</title>
<description>
<![CDATA[
Нововведение будет действовать с 1 июня в 36 подмосковных муниципалитетах
]]>
</description>
<pubDate>Fri, 20 Mar 2020 16:23:58 +0300</pubDate>
<link>/transport/15615</link>
<category>NEWS</category>
<author>Карина Мелова</author>
<guid isPermaLink="true">/transport/15615</guid>
</item>
…
</channel>
</rss>В данном случае, мы получаем такие данные:
- Наименование источника: Сейчас.ру
- Ссылка на канал: https://www.lawmix.ru/
- Заголовок: ЦИК: возможно проведение досрочного голосования по Конституции на протяжении недели
- Описание: Окончательное решение по каждому региону будут принимать избирательные комиссии на местах.
- Ссылка на новость: https://www.lawmix.ru/state/15616
- Время публикации: Fri, 20 Mar 2020 17:41:46 +0300.
Мы же будем приводить в более удобный для нас вид дату публикации и скачивать метаданные в виде файла Excel в формат xlsx. Так же статья имеет и другие метаданные которые нам не интересны (автора и категорию статьи).
Для начала работы нам нужно импортировать необходимые нам библиотеки.
import feedparser
import pandas as pd
import reТеперь создадим массив с ссылками на сайты, а так же нам нужен словарик, с помощью которых мы будем осуществлять фильтрацию.
df = pd.DataFrame(columns=['Наименование источника', 'Ссылка на канал', 'Заголовок', 'Описание', 'Ссылка на новость', 'Дата новости'])
sites = ['http://www.lawmix.ru/rss.php', 'https://www.mk.ru/rss/index.xml']
words = [r'\bВтор\S*', r'\bРосси\S*', r'\bСША\S*', r'\bГерман\S*', r'\bТурц\S*', r'\bУкраин\S*', r'\bРФ\S*']Теперь приступим к добыванию информации с rss-ссылок и обработке каждой статьи.
for site in sites:
d = feedparser.parse(site)
print("\nИдет работа с сайтом: ", site)
d.feed.title = (d.feed.title).replace('<![CDATA[ ','')
print("Наименование канала: \"", (d.feed.title).replace(']]>',''), "\"")
print('Кол-во постов (всего):', len(d.entries))
for post in range(0,len(d.entries)):
for word in words:
kol_posts_site+=1
match1 = re.search(word.lower(), (d.entries[post].description).lower())
match2 = re.search(word.lower(), (d.entries[post].title).lower())
if match1 or match2:
df.loc[post]=[d.feed.title,d.feed.link,d.entries[post].title,d.entries[post].description,d.entries[post].link,d.entries[post].published]
break
df.drop_duplicates(['Описание'],inplace=True)
df.reset_index(inplace=True)
del df['index']
df.to_excel('RSS_stat.xlsx')
В конечном счете, мы добыли информацию с сайтов, при помощи RSS.
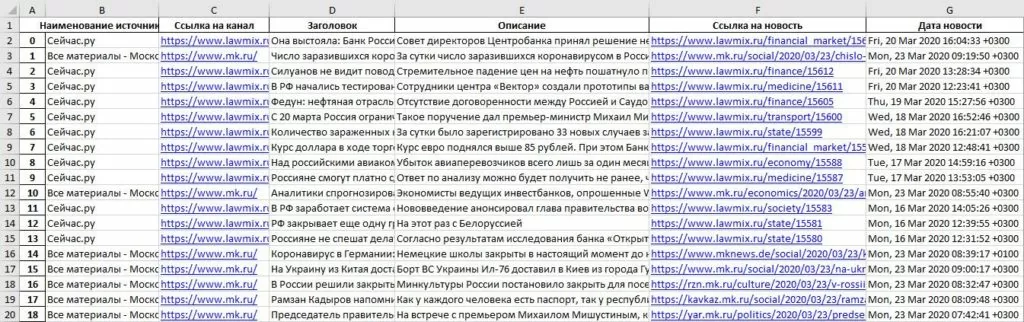
Теперь мы можем оформить их в любом удобном для нас виде и использовать в дальнейшем.