/img/star (2).png.webp)






/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Для того, чтобы машина могла получить данные из физических документов, применяются технологии оптического распознавания символов (optical character recognition, OCR). Считается, что данные технологии появились в конце XIX века. Тогда их предназначением являлось помощь слепым и плохо видящим людям в чтении. В 60-х годах XX века появились первые сканеры, а в 1984 году появился первый сканер паспортов. Главным недостатком этих технологий являлась потребность в специализированном оборудовании, что ограничивало возможный круг их пользователей. В 90-х годах появилось программное обеспечение, позволяющее считывать текст с фотографии, однако результат зачастую содержал ошибки и было необходимо проверять данные.
Наиболее распространённым инструментом для OCR до развития нейронных сетей являлся движок tesseract. Помимо него являются популярными продукты компании ABBYY, например ABBYY FineReader. Однако существуют и другие инструменты OCR, о которых знают меньшее количество человек.
Не все знают, что Google Документы предоставляют автоматическое распознавание текста из pdf-файлов и изображений размером до 2МБ. Для этого нужно выбрать файл на Google Диске и в контекстном меню при нажатии ПКМ на него выбрать «Открыть с помощью» -> Google Документы. В результате открывается документ, содержащий исходное изображение и весь распознанный текст.
Также существует разработка китайского поисковика Baidu PaddleOCR. Данная библиотека написана на Python и предоставляет доступ к большому количеству моделей на различных языках.
Проверим работу этих средств на изображениях чеков на русском и английском языках.

Проверим PaddleOCR
Код:
from paddleocr import PaddleOCR, draw_ocr # type: ignore
import os
import cv2
import paddle
import matplotlib.pyplot as plt
ocr = PaddleOCR(use_angle_cls=True,lang="en")
result = ocr.ocr(imgPath)
def saveOCR(imgPath, outPath, res):
# savePath=out_path+"Ipynb"
savePath = os.path.join(outPath, imgPath.split('/')[-1])
print(savePath)
image = cv2.imread(imgPath)
boxes = [line[0] for line in res[0]]
txts = [line[1][0] for line in res[0]]
scores = [line[1][1] for line in res[0]]
imOCR = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
cv2.imwrite(savePath, imOCR)
img = cv2.cvtColor(imOCR, cv2.COLOR_BGR2RGB)
outPath = './output_images'
saveOCR(imgPath, outPath, result)
Результат:

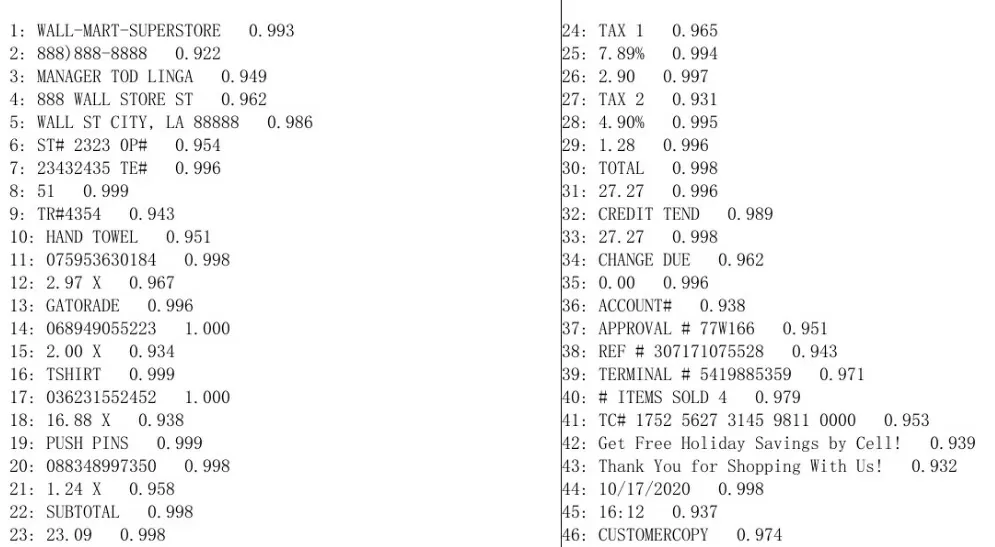
Практически весь чек был распознан с высокой уверенностью. Из ошибок: не был найден номер счета и открывающая скобка в номере.
Проверим работу Google Документов:
________________________________________
WALL-MART-SUPERSTORE
ST# 2323 OP#
HAND TOWEL
GATORADE
T-SHIRT
(888) 8888888 MANAGER TOD LINGA 888 WALL STORE ST
WALL ST CITY, LA 88888
23432435 TE# 51
TR# 4354
075953630184
2.97 X
068949055223
2.00 X
036231552452
16.88 X
PUSH PINS
088348997350
1.24 X
SUBTOTAL
23.09
TAX 1
7.89%
2.90
TAX 2
4.90%
1.28
TOTAL
27.27
CREDIT TEND
27.27
CHANGE DUE
0.00
ACCOUNT #
APPROVAL # 77W166
REF # 307171075528
TERMINAL # 5419885359
# ITEMS SOLD 4
TC# 1752 5627 3145 9811 0000
Get Free Holiday Savings by Cell! Thank You for Shopping With Us! 10/17/2020 16:12
✰✰✰ CUSTOMER COPY ✰✰✰
Видно, что Google верно распознал весь текст и даже попытался распознать оформление текста. Из недостатков можно отметить плохую группировку текста, затрудняющую дальнейшую работу с ним.
Проверим распознание чека на русском языке:

Для работы с PaddleOCR необходимо заменить параметр lang на “ru”.
Результат:


По полученным результатам можно сделать вывод, что русская модель PaddleOCR не может распознать не только текст на русском, но и числа. Интересный факт: модель на английском распознала все цифры и правильно собрала все смысловые блоки (например «Сумма операции» и др.)

Google Документы опять безошибочно извлек весь текст даже на русском языке (но снова в неудобном порядке):
ОСБ <0017>
ДАТА:
КАРТА:
ЧЕК
БАНКОМАТ <770093>
21.02.2019 15:21:51
6390 02** **** **00 42
перевод с карты на карту
ДАТА ОПЕРАЦИИ:
время операции (МСК):
идентификатор операции:
Отправитель:
Получатель:
комиссия:
Сумма операции:
Код авторизации:
ФИО:
Maestro:
21.02.19
15:21:33
984468
**** 0042
N карты: **** 4176 4 169,00 руб.
41,69 руб.
184383
Платеж исполнен
КОНТАКТНЫЙ ЦЕНТР
Для оценки качества работы OCR используются различные метрики. Наиболее простыми и распространенными являются Character Error Rate и Word Error Rate (CER и WER)– количество замен, вставок или удалений символов, или слов соответственно, необходимых для того, чтобы получить истинный текст. Данные метрики реализованы в модуле torchmetrics. Для OCR приемлемым значением CER считается примерно 10%, очень хорошим – менее 1%. Найдем значение данной метрики у рассмотренных моделей на датасете из 10 документов на английском языке. У модели из Google Документов значение метрики составило примерно 1.7%, у модели от PaddleOCR – 7.3%.
Странный порядок чтения, отсутствие дополнительной информации о тексте (например, границ найденных фрагментов с текстом) и необходимость загрузки файлов на Google Диск делают практически невозможным использование встроенных в Google Документы OCR в серьезных рабочих целях. Однако простота интерфейса, отсутствие необходимости писать код и довольно хорошие результаты «из коробки» делает их очень удобным инструментом для решения бытовых проблем.
PaddleOCR же можно использовать для распознавания английского (и китайского) текста и в рабочих целях, но модель для русского языка нуждается в доработке. Еще одним значительным недостатком является очень сильная ориентация на китайский рынок, в связи с чем документация на английском языке переведена с опозданием и неточностями. Из преимуществ можно отметить возможность дотренировать модель для работы с конкретным шрифтом, размером текста, что позволяет повысить качество обработки документов определенного формата.