/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Готовых наборов данных русских текстов для тематического моделирования на просторах Интернета практически нет, поэтому возможности библиотеки BigArtm будут продемонстрированы на комментариях пользователей к одному из постов официального сообщества «Круглосуточные новости Екатеринбурга E1.RU» во «ВКонтакте». Задача – проанализировать, о чем пишут люди, иначе говоря, какие темы их интересуют.
Выгружать комментарии будем с помощью API «ВКонтакте» на Python. Импортируем необходимые библиотеки.
import vk_api
import pandas as pd
Авторизуемся в социальной сети с помощью логина и пароля. Далее, парсим комментарии с последнего поста новостного сообщества и записываем в DataFrame с помощью vk.wall.getComments() (более подробно с параметрами функции можно ознакомиться в документации ). На момент выгрузки к последнему посту о проблемах жителей Екатеринбурга, связанных с введением QR-кодов, всего пользователи оставили 43 комментария. Все они попали в выгрузку.
0 Магазин техники в Кольцово коды ввели.
1 Надо сделать ключи и закинуть денег за кредит....
2 Да никаких проблем. ТЦ, рестораны, библиотеки ...
3 Мегамарт на Луначарского 205 - не пустили без ...
4 Подскажите пожалуйста, в ГАИ ГИБДД вход по куа...
5 Без проблем: показал охраннику на входе в ТЦ к...
6 Вообще никаких проблем не заметил.
7 В ресторане нельзя заказать на вынос, хотя пис...
8 автобусы с утра переполнены - вроде бы сказали...
9 Есть код - нет проблем))
Переходим к разделению комментариев пользователей по тематикам. Для этого импортируем необходимые библиотеки.
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from pymorphy2 import MorphAnalyzer
import artm
Затем производим предварительную обработку комментариев. Удаляем символы, смайлы, стоп-слова (например, местоимения, междометия). А также применяем лемматизацию – метод приведения слова к нормальной (начальной) форме и удаляем пустые строки.
def preprocessing(data, column, col_to):
data=data.drop_duplicates(subset=[column])
data=data.dropna(subset=[column]) #удалим дубликаты
data[col_to] = data[column].str.replace(r'[a-zA-Z0-9-_]', ' ').str.replace(r'[^a-яА-я]', ' ').str.replace(r'\W', ' ').str.replace(r'\s+',' ').str.lower()
return data
def lemmatize(text):
addit = ['наш', 'ваш', 'твой', 'свой', 'это']
stop_rus = stopwords.words('russian')
stop_rus.extend(addit)
morph = MorphAnalyzer()
text = ' '.join([morph.parse(word)[0].normal_form for word in text.split() if word not in stop_rus])
return text
data = preprocessing(data, 'text', 'text')
data.text = data['text'].apply(lemmatize)
data = data.loc[data.text!=''].reset_index()
Осталось 36 комментариев. Однако, такой обработки недостаточно для модели BigARTM. Исходные данные должны быть представлены в специальном формате «vowpal wabbit». Это, так называемый, «мешок слов», где каждая новая строка содержит слова, употребляемые в рамках документа. Эта информация записывается после тега |text.
def to_vw_format(document):
return '|text ' + ' '.join(word for word in document.split())
f = open('documents.txt', 'w')
vw = data.text.apply(to_vw_format)
for i in range(0,len(vw)):
f.write(str(vw.values[i])+ '\n')
f.close()
Наконец, разделяем набор данных на специальные части («Batch»). В нашем случае Batch будет единственным).
batch_vect = artm.BatchVectorizer(data_path='documents.txt',
data_format='vowpal_wabbit',
target_folder='batch_vect')
Далее создаем словарь со всеми словами из всех текстов, который необходим для дальнейшей кластеризации.
dict = artm.Dictionary()
dict.gather(data_path='batch_vect')
dict.save_text(dictionary_path='batch_vect/my_dict.txt')
Опционально в словаре можно отфильтровать часто встречающиеся (слова, которые не несут смысловой нагрузки, например, «идти», «вы») или редко встречающиеся слова (опечатки, словоформы) специальной функцией:
dict.filter(min_tf=int, max_tf=int)где min_tf — минимальное количество употребления слова во всех документах, max_tf – максимальное.
Выполняем тематическое моделирование (в общем случае, без регуляризаторов). Здесь проявляются некоторые недостатки модели – необходимость вручную подбирать количество тем, количество проходов по набору документов, а также плохо интерпретируемые числовые метрики, такие как перплексия (количественная метрика оценки качества работы модели BigArtm, отражает степень сходимости модели).
theme_mod = artm.ARTM(num_topics = 10, dictionary=dict, cache_theta= True) #theta – матрица вероятностей принадлежности каждого текста каждой тематике
theme_mod.scores.add(artm.PerplexityScore(name='my_first_perplexity_score', dictionary=dict)) #метрика оценки модели – перплексия
theme_mod.scores.add(artm.TopTokensScore(name='TopTokensScore', num_tokens=5)) #метрика оценки модели – топ 5 (num_tokens) слов по каждой тематике
theme_mod.initialize(dictionary=dict)
theme_mod.fit_offline(batch_vectorizer=batch_vect, num_collection_passes=10)
Наиболее интерпретируемая метрика оценки модели – топ (в нашем случае, 5) слов по каждой тематике. Иначе говоря, ключевые слова.
for theme in theme_mod.topic_names:
print(theme + ": ")
print(theme_mod.score_tracker['TopTokensScore'].last_tokens[theme])
topic_0:
['медотвод', 'который', 'так', 'тест', 'работа']
topic_1:
['автобус', 'каждый', 'дом', 'орать', 'выходной']
topic_2:
['закон', 'заставить', 'продавец', 'персональный', 'охрана']
topic_3:
['слово', 'торговый', 'центр', 'предоставить', 'вакцина']
topic_4:
['заказывать', 'вынос', 'писать', 'делать', 'ресторан']
topic_5:
['проблема', 'никакой', 'деньга', 'ключ', 'магазин']
topic_6:
['человек', 'паспорт', 'почему', 'должный', 'друг']
topic_7:
['проблема', 'код', 'доставка', 'работать', 'вакцина']
topic_8:
['код', 'тц', 'проблема', 'нужный', 'подсказать']
topic_9:
['вообще', 'вс', 'какой', 'государство', 'тот']
Среди комментариев есть те, которые нельзя отнести к какой-либо тематике. Такие тексты скидываются в какую-либо из тем, поэтому, довольно часто не все темы можно однозначно определить.
Так, из полученных 10 тематик можно выделить: проблемы, связанные с медотводом от вакцинации, пропускным режимом в автобусах, торговых центрах, с работой ресторанов и доставки, а также отдельная тема об отсутствии каких-либо проблем у горожан.
BigARTM также проставляет вероятности отнесения текста к той или иной тематике. Это означает, что один текст может быть отнесен к нескольким темам, что повышает точность и интерпретируемость результатов алгоритма. Вероятности можно посмотреть, используя следующую функцию:
theme_mod.get_theta().transpose()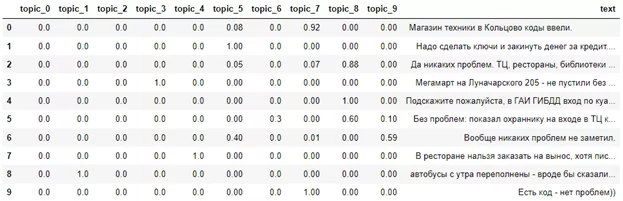
Таким образом, комментарии пользователей были разделены на 10 тем с помощью библиотеки BigARTM. Для увеличения точности моделирования возможно использование регуляризаторов, дополнительных проходов по коллекции документов, а также более точной настройки параметров и фильтрации словаря.