/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В этой статье я расскажу об одном из методов для устранения дисбаланса предсказываемых классов. Важно уточнить, что многие методы, которые строят вероятностные модели, прекрасно работают и без устранения несбалансированности. Однако, когда мы переходим к построению невероятностных моделей или когда рассматриваем задачу классификации с большим количеством классов, стоит озаботиться решением проблемы дисбаланса классов.
Если не бороться с этой проблемой, то модель будет перегружена бо́льшим классом, в следствии будет игнорировать меньший класс, неправильно классифицировать его, поскольку модели будет не хватать примеров и свойств редкого класса. Таким образом, несбалансированность классов напрямую влияет на точность и качество результатов машинного обучения.
Метод NearMiss — это метод недостаточной выборки. Он пробует сбалансировать распределение классов путём случайного исключения наблюдений из бо́льших классов. Если экземпляры из двух разных классов очень похожи между собой, метод удаляет наблюдение из мажоритарного класса.
Давайте рассмотрим работу этого метода на практике. Для начала установим необходимые нам библиотеки через стандартный pip в cmd:
pip install pandas
pip install numpy
pip install sklearn
pip install imblearn
Я буду использовать набор данных о сессиях, связанных с поведением пользователей на веб-страницах онлайн-магазина.
import pandas as pd
import numpy as np
df = pd.read_csv('online_shoppers_intention.csv')
df.shape
(12330, 18)
Столбец для прогнозирования называется «Revenue» и может принимать 2 значения: True (пользователь совершил покупку) и False (пользователь не совершил покупку). Посмотрим, какое количество наблюдений приходится на каждый из классов.
df['Revenue'].value_counts()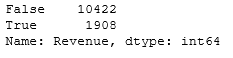
Как видно, классы являются несбалансированными, поскольку делятся примерно в соотношении 85% и 15%.
Разделим наблюдения на обучающую и тестовую выборки:
Y = df['Revenue']
X = df.drop('Revenue', axis = 1)
feature_names = X.columns
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 97)
Посмотрим на размерность сформированных наборов данных:
print('Размерность набора данных X_train: ', X_train.shape)
print('Размерность набора данных Y_train: ', Y_train.shape)
print('Размерность набора данных X_test: ', X_test.shape)
print('Размерность набора данных Y_test: ', Y_test.shape)

Далее воспользуемся логистической регрессией и выведем отчёт с основными показателями классификации.
from sklearn.linear_model import LogisticRegression
lregress1 = LogisticRegression()
lregress1.fit(X_train, Y_train.ravel())
prediction = lregress1.predict(X_test)
print(classification_report(Y_test, prediction))
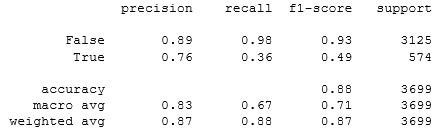
Отметим, что точность модели 88%. Колонка «recall» показывает меру полноты классификатора, способность классификатора правильно находить все положительные экземпляры. Из неё видно, что отзыв миноритарного класса гораздо меньше, то есть модель более склонна к классу большинства.
Перед применением метода NearMiss выведем количество наблюдений каждого класса:
print('Перед применением метода кол-во меток со значением True: {}'.format(sum(y_train == True)))
print('Перед применением метода кол-во меток со значением False: {}'.format(sum(y_train == False)))
Перед применением метода количество меток со значением True: 1334
Перед применением метода количество меток со значением False: 7297
Теперь воспользуемся методом и выведем количество наблюдений каждого класса.
from imblearn.under_sampling import NearMiss
nm = NearMiss()
X_train_miss, Y_train_miss = nm.fit_resample(X_train, Y_train.ravel())
print('После применения метода кол-во меток со значением True: {}'.format(sum(Y_train_miss == True)))
print('После применения метода кол-во меток со значением False: {}'.format(sum(Y_train_miss == False)))
После применения метода количество меток со значением True: 1334
После применения метода количество меток со значением False: 1334
Видно, что метод сравнял классы, уменьшив размерность доминирующего класса. Воспользуемся логистической регрессией и выведем отчёт с основными показателями классификации.
lregress2 = LogisticRegression()
lregress2.fit(X_train_miss, Y_train_miss.ravel())
prediction = lregress2.predict(X_test)
print(classification_report(Y_test, prediction))
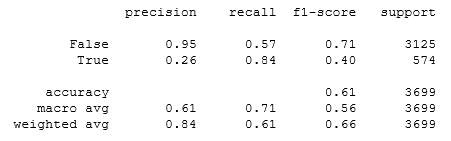
Значение отзывов меньшинства повысилось до 84%. Но из-за того, что выборка большего класса значительно уменьшилась, понизилась точность модели до 61%. Таким образом, этот метод действительно помог справиться с несбалансированностью классов.