/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
Модель поиска похожих изображений
Поиск похожих изображений — очень активная и быстро развивающаяся область исследований в последнее десятилетие. Исследования в данной области позволили разработать модели, которые могут помочь в работе в различных областях, например:
— чтобы найти похожие изображения;
— поиск фотографий-плагиатов;
— создание возможностей для обратных ссылок;
— знакомство с людьми, местами и продуктами;
— поиск товаров по фотографии;
— обнаружение поддельных аккаунтов, поиск преступников и т.д.
Наиболее известными системами являются Google Image Search и Pinterest Visual Pin Search. В посте будет проведено знакомство с созданием простой системы поиска похожих изображений с использованием специального типа нейронной сети, называемой автоэнкодер. Изображения в данном способе не используют меток, т.е. дополнительных текстовых или числовых элементов, которые классифицируют изображения по категориям. Извлечение признаков из изображения будет происходить только с помощью их визуального содержимого (текстуры, формы, …). Этот тип извлечения изображений называется поиск изображений на основе содержимого (CBIR), в отличие от поиска ключевых слов или изображений на основе текста.
CBIR при использовании глубокого обучения и поиска изображений можно назвать формой обучения без учителя:
- При обучении автоэнкодера не используется никаких меток для классов
- Автоэнкодер используется для преобразования изображения в векторное представление (т. е. нашего “вектора признаков” для данного изображения)
- Затем, во время поиска похожих изображений, вычисляется расстояние между векторами преобразованных изображений — чем меньше расстояние, тем более релевантными/визуально похожими являются два изображения.
В посте будут освещены следующие разделы:
- Загрузка данных и работа с данными
- Сверточные автоэнкодеры для извлечения признаков из изображения
- Построение модели подобия изображений при помощи K ближайших соседей (NearestNeighbours)
- Использование предобученных моделей для извлечения признаков из изображения
- Выводы
Загрузка данных и работа с данными
Для построения модели нужны данные – изображения, с которыми будет проведена работа. В качестве данных был использован открытый набор изображений, который называется Caltech-101, который содержит около 9000 изображений, которые разделены на 101 тему (самолеты, машины, животные и т.д.).
Работа начинается с импорта необходимых библиотек и модулей из Keras и Tensorflow.
import os
import keras
from keras.preprocessing import image
from keras.applications.imagenet_utils import decode_predictions, preprocess_input
from keras.models import Model
from tensorflow.keras import applications
import tensorflow as tf
from tensorflow.keras.models import save_model
import tensorflow.keras.layers as L
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import cv2
import pandas as pd
import tqdm
from skimage import io
import glob
После импорта библиотек нужно загрузить сами изображения. Для этого нужно полностью прописать путь до папки, где хранятся изображения, и создать список из путей до каждого изображения.
path ="/Users/Desktop/Python_Scripts/101_ObjectCategories"
#we shall store all the file names in this list
filelist = []
for root, dirs, files in os.walk(path):
for file in files:
#append the file name to the list
filelist.append(os.path.join(root,file))
Далее, при помощи написанной функции было загружено 200 изображений (для экономии времени и ресурсов компьютера, если характеристики компьютера позволяют, то можно загрузить все 9000). Для этого были выполнены следующие шаги:
- Чтение изображений с помощью открытого модуля cv2;
- Преобразование изображений из BGR (синий, зеленый, красный) в RGB (красный, зеленый, синий);
- Изменение размера формы изображения на (224,224,3);
- Нормализация данных.
def image2array(filelist):
image_array = []
for image in filelist[:200]:
img = io.imread(image)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224,224))
image_array.append(img)
image_array = np.array(image_array)
image_array = image_array.reshape(image_array.shape[0], 224, 224, 3)
image_array = image_array.astype('float32')
image_array /= 255
return np.array(image_array)
train_data = image2array(filelist)
print("Length of training dataset:", train_data.shape)
В датасете почти ~ 9 тыс. изображений. Загрузка его в оперативную память и обработка каждого изображения с любым другим изображением потребует больших вычислительных затрат и может привести к сбою системы (GPU или TPU), или запуск модели будет очень дорогостоящим с вычислительной точки зрения.
Таким образом, в качестве решения можно интегрировать как сверточные нейронные сети, так и идеи автоэнкодирования для уменьшения информации из данных на основе изображений. Это будет рассматриваться как этап предварительной обработки для применения к кластеру.
Сверточные автоэнкодеры для извлечения признаков из изображения
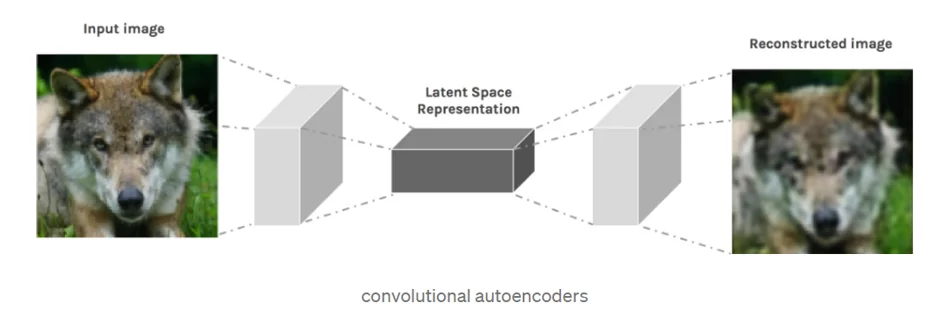
Сверточные автоэнкодеры (CAEs) — это тип сверточных нейронных сетей. Основное различие между ними заключается в том, что CAE — это неконтролируемые модели обучения (без учителя).
Он пытается сохранить пространственную информацию входных данных изображения такой, какая она есть, и аккуратно извлекать информацию.
- Энкодеры: преобразование входного изображения в представление скрытого пространства с помощью серии сверточных операций.
- Декодеры: пытаются восстановить исходное изображение из скрытого пространства с помощью серии операций свертки с повышением дискретизации / транспонирования. Также известен как деконволюция.
Подробнее о сверточных автокодерах можно прочитать здесь.
Сам автоэнкодер строится при помощи соединения сверточных слоев и слоёв пуллинга, которые уменьшают размерность изображения (сворачивают его) и извлекают наиболее важные признаки. На выходе возвращаются encoder и decoder. Для задачи кодирования изображения в вектор, нам нужен слой после автоэнкодера, т.е. векторное представление изображения, которое в дальнейшем будет использоваться для поиска похожих изображений.
Применение функции summary() к модели покажет описание работы модели слой за слоем. Нужно следить за тем, чтобы размер изображения на входе соответствовал размеру изображения на выходе декодера.
IMG_SHAPE = x.shape[1:]
def build_deep_autoencoder(img_shape, code_size):
H,W,C = img_shape
# encoder
encoder = tf.keras.models.Sequential() # инициализация модели
encoder.add(L.InputLayer(img_shape)) # добавление входного слоя, размер равен размеру изображения
encoder.add(L.Conv2D(filters=32, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=64, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=128, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=256, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Flatten())
encoder.add(L.Dense(code_size))
# decoder
decoder = tf.keras.models.Sequential()
decoder.add(L.InputLayer((code_size,)))
decoder.add(L.Dense(14*14*256))
decoder.add(L.Reshape((14, 14, 256)))
decoder.add(L.Conv2DTranspose(filters=128, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=64, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=32, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=3, kernel_size=(3, 3), strides=2, activation=None, padding='same'))
return encoder, decoder
encoder, decoder = build_deep_autoencoder(IMG_SHAPE, code_size=32)
encoder.summary()
decoder.summary()

Параметры и обучение модели:
inp = L.Input(IMG_SHAPE)
code = encoder(inp)
reconstruction = decoder(code)
autoencoder = tf.keras.models.Model(inputs=inp, outputs=reconstruction)
autoencoder.compile(optimizer="adamax", loss='mse')
autoencoder.fit(x=train_data, y=train_data, epochs=10, verbose=1)
В качестве оптимизатора модель использует ‘adamax’, в качестве функции потерь метрику mse. Автоэнкодер проходит 10 эпох (т.е. 10 раз) по данным для лучшего обучения.
Извлечение признаков из изображения, как было сказано выше, состоит из того, что после того как сработал энкодер и перед обратным декодированием, нужно взять слой из модели, который отвечает за кодирование изображения и сохранить его. Таким образом, сохраняться все кодированные представления изображения.
images = train_data
codes = encoder.predict(images)
assert len(codes) == len(images)
Построение модели подобия изображений при помощи K ближайших соседей (NearestNeighbours)
После получения представления сжатых данных всех изображений мы можем применить алгоритм N-ближайших соседей для поиска похожих изображений. Он основан на расчете евклидового расстояния между изображениями, те расстояния, которые будут меньше всего, будут означать, что изображения похожи.
from sklearn.neighbors import NearestNeighbors
nei_clf = NearestNeighbors(metric="euclidean")
nei_clf.fit(codes)
Для отображения похожих изображений были написаны две функции, которые показывают 5 ближайших/похожих фотографий на ту, с которой идет сравнение.
def get_similar(image, n_neighbors=5):
assert image.ndim==3,"image must be [batch,height,width,3]"
code = encoder.predict(image[None])
(distances,),(idx,) = nei_clf.kneighbors(code,n_neighbors=n_neighbors)
return distances,images[idx]
def show_similar(image):
distances,neighbors = get_similar(image,n_neighbors=3)
plt.figure(figsize=[8,7])
plt.subplot(1,4,1)
plt.imshow(image)
plt.title("Original image")
for i in range(3):
plt.subplot(1,4,i+2)
plt.imshow(neighbors[i])
plt.title("Dist=%.3f"%distances[i])
plt.show()
Результаты работы автоэнкодеров можно оценить положительно, т.к. были найдены похожие фотографии:
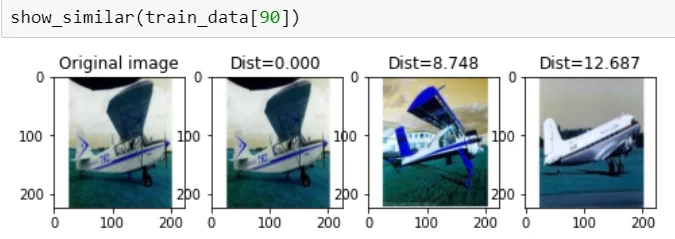
(первое изображение то же самое, т.к. фотография сравнивает с изображениями из одного датасета)

Использование предобученных моделей для извлечения признаков из изображения
Помимо использования автоэнкодеров для получения признаков из изображения можно использовать уже предобученные модели для классификации. Таких моделей очень много, и они также используют сверточные слои и слои пуллинга для получения признаков. Возникает логичный вопрос, зачем же тогда использовать автоэнкодеры?
Во-первых, предобученные модели могли быть созданы для других целей и могут не подойти по входным параметрам или по самой конструкции нейронной сети для вашей задачи, поэтому придется её перестраивать или строить сеть самому.
Во-вторых, предобученные модели на выходе могут получать не тот размер изображения, который нужен и при загрузке датасета и преобразовании изображений в вектор может не хватить памяти и мощности компьютера, а также это будет занимать много времени. Поэтому, если использовать предобчуенные модели, то нужно использовать метод понижения размерности PCA, который уменьшит размерность полученных векторов и позволит не нагружать компьютер. При этом автоэнкодеры сразу понижают размерность и можно его настроить таким образом, чтобы на выходе получался вектор необходимого размера.
Плюсами применения предобученных моделей является то, что нет необходимости строить нейронную сеть, настраивать сверточные слои, нужно просто взять нужный слой и использовать его для своих целей. Также такие модели были обучены на больших датасетах и имеют лучшие веса (настройки) для извлечения необходимых признаков, они лучше выделяют важные области на изображении.
Для того, чтобы использовать предобученные модели, для начала их нужно загрузить. В качестве примеры, была взята модель VGG16 – сверточная сеть, с 13-ю слоями, которая была обучена на миллионных датасетах.
model = keras.applications.vgg16.VGG16(weights='imagenet', include_top=True)
model.summary()
Для загрузки изображений была написана специальная функция:
def load_image(path):
img = image.load_img(path, target_size=model.input_shape[1:3])
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return img, x
Модель VGG16 используется для классификации изображений, т.е. определение темы, к которой относится изображение (самолет, вертолет и т.д.), поэтому в конце она имеет слой для классификации. Все предыдущие слои сворачивают и кодируют изображение в вектор, поэтому они нужны. Данную модель можно полностью скопировать с удалением последнего слоя, таким образом получим модель, которая только кодирует изображение в вектор.
feat_extractor = Model(inputs=model.input, outputs=model.get_layer("fc2").output)
feat_extractor.summary()

После того как модель построена, применяем её к данным, получаем вектор признаков каждого изображения, применяем метод понижения размерности PCA.
import time
tic = time.perf_counter()
features = []
for i, image_path in enumerate(filelist[:200]):
if i % 500 == 0:
toc = time.perf_counter()
elap = toc-tic;
print("analyzing image %d / %d. Time: %4.4f seconds." % (i, len(images),elap))
tic = time.perf_counter()
img, x = load_image(path);
feat = feat_extractor.predict(x)[0]
features.append(feat)
print('finished extracting features for %d images' % len(images))
from sklearn.decomposition import PCA
features = np.array(features)
pca = PCA(n_components=100)
pca.fit(features)
pca_features = pca.transform(features)
Следующий код показывает, как случайно выбирается картинка из датасета, сравнивается расстояние от этой картинки до всех изображений в датасете, данные расстояния сортируются по возрастанию расстояния и выбираются наиболее близкие/похожие.
Как можно заметить предобученные модели также хорошо справляются с поставленной задачей по поиску похожих изображений.
from scipy.spatial import distance
similar_idx = [ distance.cosine(pca_features[80], feat) for feat in pca_features ]
idx_closest = sorted(range(len(similar_idx)), key=lambda k: similar_idx[k])[1:6] # отображение первых 6 похожих изображений
thumbs = []
for idx in idx_closest:
img = image.load_img(filelist[idx])
img = img.resize((int(img.width * 100 / img.height), 100))
thumbs.append(img)
# concatenate the images into a single image
concat_image = np.concatenate([np.asarray(t) for t in thumbs], axis=1)
# show the image
plt.figure(figsize = (16,12))
plt.imshow(concat_image)


Выводы:
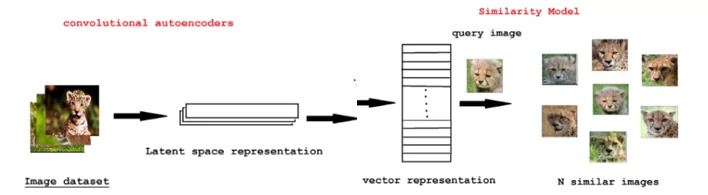
Таким образом был построен алгоритм для распознавания и поиска похожих изображений в наборе данных при помощи кодирования изображений в векторную форму. Данный алгоритм хорошо работает, но его всегда можно улучшить, например, путем добавления новых слоев или предварительной обработки изображений. В целом алгоритм можно представить следующими шагами:
Шаг 1: Берем имя файла или URL-адрес и преобразуем это изображение в нужную векторную форму.
Шаг 2: используя эту форму, извлекаем важные признаки из изображения и преобразуем его в вектор при помощи автоэнкодера или предобученной модели.
Шаг 3: извлеченные признаки-вектора сравниваются с набором других векторов и находятся похожие изображения на основе расстояний: чем меньше расстояния, тем более похожи изображения.
Шаг 4: Отображение результатов.
Полезные ссылки:
http://www.vision.caltech.edu/datasets/ — ссылки на датасет
https://pgaleone.eu/neural-networks/2016/11/24/convolutional-autoencoders/ — о сверточных автоэнкодерах
https://habr.com/ru/post/348000/ — про построение сверточных нейронных сетей