/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Задача – «Провести анализ сообщений коммерческого чата на предмет игнорирования вопроса клиента менеджером компании»
На входе: лог чатов с клиентом компании в csv формате:
| Дата отправки | Сообщение | Кто отправил | Номер заявки |
| yyyy-mm-dd hh-mm-ss | Текст1 | Отправитель1 | Номер1 |
| yyyy-mm-dd hh-mm-ss | Текст2 | Отправитель2 | Номер2 |
| yyyy-mm-dd hh-mm-ss | Текст3 | Отправитель3 | Номер3 |
| yyyy-mm-dd hh-mm-ss | Текст4 | Отправитель4 | Номер4 |
| yyyy-mm-dd hh-mm-ss | текстN | отправительN | НомерN |
План решения:
1. Подготовка данных
2. Выбор инструмента для определения похожих сообщений внутри каждого чата
3. Анализ полученных результатов
4. Подведение итогов
Подготовка данных
Применяются следующие инструменты:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import tqdm
import pandas as pd
import numpy as np
import re
import time
from nltk.tokenize import sent_tokenize, word_tokenize
import pymorphy2
morph = pymorphy2.MorphAnalyzer(lang='ru')
from nltk import edit_distance
import editdistance
import textdistance
from jellyfish import levenshtein_distance
Выполнена загрузка CSV файлов в DataFrame. Форматы дат в разных логах отличаются, поэтому они приведены к единому виду. Сортировка выполнена по номерам чатов и датам сообщений, также проводиться сброс/упорядочивание индексов.
df = pd.DataFrame()
counter = 1
for path_iter in PATH:
print(path_iter)
df_t = pd.read_csv(path_iter, sep=';', encoding='cp1251', dtype='str', engine = 'python')
if counter == 1:
df_t['Дата отправки'] = pd.to_datetime(df_t['Дата отправки'], format='%d.%m.%y %H:%M')
else:
df_t['Дата отправки'] = pd.to_datetime(df_t['Дата отправки'], format= '%Y-%m-%d %H:%M:%S')
df = df.append(df_t)
counter += 1
df.sort_values(by=['Номер заявки', 'Дата отправки'], inplace=True)
df.reset_index(drop=True, inplace=True)
print('Размер DF, rows =', len(df))
df.head()
>>>
Размер DF, rows = 144584

На основании группировки делаем вывод, что основная часть сообщений чата приходиться на клиентов и консультантов компании. Изредка наблюдаются автоматические сообщения системы.
df['Кто отправил'].value_counts()
>>>
['AGENT'] 43137
['CONSULTANT'] 33040
['USER'] 29463
['MANAGER'] 21257
[] 13939
['BOT'] 3748
Name: Кто отправил, dtype: int64
print('Кол-во уникальных чатов', len(set(df['Номер заявки'].tolist())))
>>>
Количество уникальных чатов 5406
Размер большинства чатов – 25 сообщений.
df['Номер заявки'].value_counts().hist(bins = 40)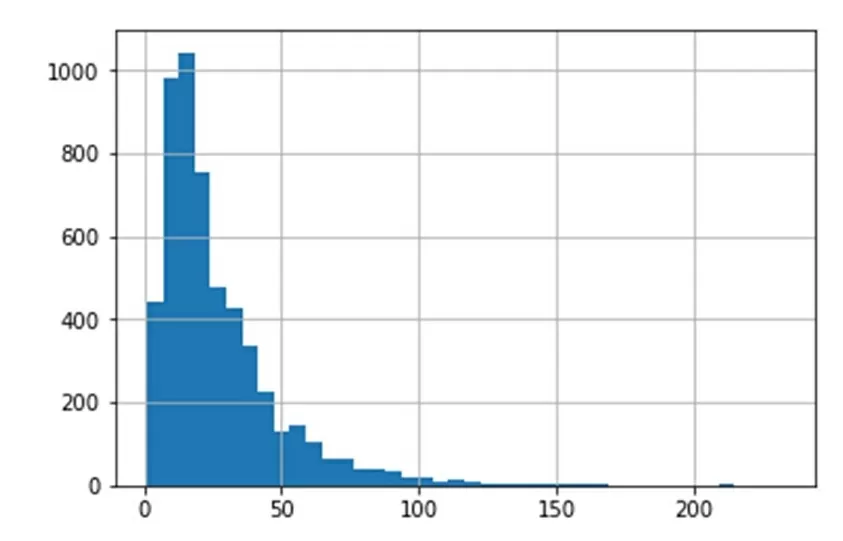
Проведена обработка текста: нижний регистр, игнорирование сообщений с одним словом, оставляем только русские буквы, пробел и тире. Удалены из сообщений тексты о вложениях документов вида «картинка.jpg».
def filter_text(text):
'''
принимает текст,
на выходе обработанные текст.
в тексте остаются только символы русского алфавита, тире, пробел
'''
text = text.lower()
if len(re.findall(r'[\w]+', text)) == 1:
#print(re.findall(r'[\w]+', text), '---', len(re.findall(r'[\w]+', text)))
return ''
#удаляем из сообщений тексты с вложениями документов вида "картинка.jpg"
text = re.sub(r'(.+[.]jpg)|(.+[.]pdf)', '', text)
text = [c for c in text if c in 'абвгдеёжзийлкмнопрстуфхцчшщъыьэюя- ']
text = ''.join(text)
return text
df['work_text'] = df.apply(lambda row: filter_text(row['Сообщение']), axis = 1)
Заменяем несколько пробелов одним пробелом.
df['work_text'] = df.apply(lambda row: re.sub(r'\s+', ' ', row['work_text']) , axis = 1)Чистим от частотных/не значимых словосочетаний:
STOP_WORDS = [
'-', '--', '-а', '-б', '-в', '-е', '-й', '-к', '-м', '-т', '-у', '-х', '-ю', '-я', 'а', 'а-', 'аа', 'аб',
'ав', 'ад', 'ае', 'аж', 'ак', 'ам', 'ан', 'ао', 'ап', 'ас', 'ау', 'ач', 'б', 'ба', 'бв', 'бд', 'без', 'бы',
'в', 'в-', 'ва', 'вб', 'вв', 'вг', 'ви', 'вм', 'вн', 'во', 'вп', 'вс', 'вт', 'вх', 'вщ', 'вы', 'вю', 'г',
'г-', 'га', 'гв', 'гк', 'гм', 'го', 'гп', 'гу', 'д', 'да', 'дб', 'дв', 'дд', 'де', 'день', 'ди', 'дк', 'для',
'до', 'доброе', 'добрый', 'др', 'дс', 'ду', 'дю', 'дя', 'е', 'еа', 'ев', 'ее', 'ей', 'ен', 'ес', 'ею', 'её',
'ж', 'же', 'жк', 'жр', 'з', 'за', 'здравствуйте', 'зп', 'зу', 'и', 'иа', 'из', 'ик', 'ил', 'или', 'им', 'ин',
'ио', 'ип', 'иу', 'их', 'й', 'к', 'ка', 'как', 'кв', 'кд', 'кк', 'км', 'ко', 'кп', 'кр', 'кс', 'л', 'ла',
'лд', 'ли', 'лк', 'ля', 'м', 'ма', 'мб', 'мв', 'мг', 'мз', 'ми', 'мк', 'мл', 'мм', 'мне', 'мо', 'мр', 'мс',
'мт', 'му', 'мы', 'мэ', 'мю', 'мя', 'н', 'на', 'нв', 'не', 'ни', 'нн', 'но', 'нп', 'нс', 'ну', 'нф', 'ны',
'ня', 'о', 'оа', 'об', 'ов', 'од', 'ое', 'ой', 'ок', 'ом', 'он', 'оо', 'оп', 'ос', 'от', 'ох', 'оч', 'ою',
'п', 'пв', 'пи', 'пк', 'пл', 'пм', 'пн', 'по', 'пожалуйста', 'пп', 'пр', 'при', 'пс', 'пт', 'пф', 'пш',
'пю', 'р', 'ра', 'рб', 'рв', 'рд', 'ри', 'рн', 'ро', 'рп', 'рр', 'рс', 'рт', 'ру', 'рф', 'с', 'са', 'сб',
'св', 'сг', 'се', 'сж', 'ск', 'сл', 'см', 'сн', 'со', 'сп', 'спасибо', 'ср', 'ст', 'су', 'сх', 'сч', 'т',
'т-', 'та', 'тб', 'тв', 'тг', 'тд', 'те', 'ти', 'тк', 'тн', 'то', 'тп', 'тр', 'ту', 'тц', 'тч', 'ты', 'у',
'ув', 'уж', 'ук', 'ул', 'ур', 'утро', 'ух', 'уч', 'уя', 'ф', 'фг', 'фд', 'фз', 'фн', 'фф', 'фц', 'х', 'хг',
'хм', 'хо', 'ц', 'цб', 'цн', 'ч', 'чб', 'че', 'чп', 'чс', 'чт', 'что', 'ш', 'ы', 'ь', 'э', 'эг', 'эл', 'эп',
'эр', 'эт', 'эх', 'ю', 'юа', 'юв', 'юг', 'юл', 'юр', 'юс', 'я', 'яг', 'яя', 'ё',
'я', 'сейчас', 'это', 'ещё', 'понятно', 'отлично', 'извинить','извините','где'
]
#DF только с сообщениями клиентов
df_users = df[df['Кто отправил'] == '''['USER']''']
[df_users.work_text.replace(x, '', regex=True, axis = 1, inplace=True) for x in STOP_SENTS]
Приводим слова к нормальной форме, удалим из текста частотные слова
def normalize_text(text):
'''
идем по всем токенам,
то что в STOP_WORDS - выкидываем,
меняем каждый на нормальную форму,
соединяем пробелом,
возвращаем текст
'''
ls = list()
for word in word_tokenize(text, language='russian'):
if word not in STOP_WORDS:
ls.append(morph.parse(word)[0].normal_form)
norm_text = ' '.join([x for x in ls])
return norm_text
df_users['clear_text'] = df_users.work_text
df_users['clear_text'] = df_users.apply(lambda row: normalize_text(row.clear_text), axis = 1)
Выбор инструмента для поиска похожих сообщений внутри каждого чата
Найдем расстояние Левенштейна всех заявок по всем текстам:
def get_edit_distance(sec_posts, val_leven):
'''
sec_posts - list с постами чата
val_leven - коэффициент редакционного расстояния по Левенштейну:
ratio_ed = editdistance / длину текста
'''
ls = []
len_sec_posts = len(sec_posts)
sec_posts_iter = 0
for i in sec_posts:
sec_posts_iter += 1 #не проходим по тем элементам, которые уже сравнили
for k in sec_posts[sec_posts_iter:]:
#ed = edit_distance(i, k)
#ed = textdistance.levenshtein(i, k)
#ed = levenshtein_distance(i, k)
ed = editdistance.eval(i, k)
if len(k) == 0:
ratio_ed = 0
else:
ratio_ed = ed / len(k)
if len(k) !=0 and len(i) != 0 and ratio_ed <= val_leven:
ls.append([i, k, ratio_ed, ed])
#list [post1, post2, ratio_ed, ed]
return ls
CURRENT_LEV_VALUE = 0.25
#Уникальные номера заявок:
number_orders = set(df_users[(df_users['Кто отправил'] == '''['USER']''')]['Номер заявки'].tolist())
#Найдем расстояния Левенштейна по всем фразам, всех заявок:
all_dic = {}
for i_order in tqdm.tqdm(number_orders):
posts_list = df_users[(df_users['Кто отправил'] == '''['USER']''') & (df_users['Номер заявки'] == i_order)]['clear_text'].tolist()
all_dic[i_order] = get_edit_distance(posts_list, CURRENT_LEV_VALUE)
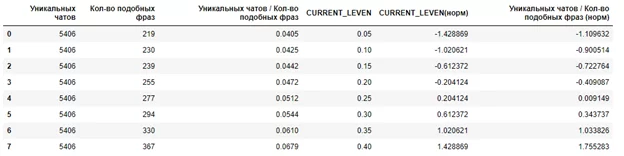
В результате тестирования была обнаружена самая производительная библиотека для расчета редакционного расстояния Левенштейна – editdistance.
Расчет затраченного времени в секундах на обработку 29463 сообщений чата представлен ниже. В тесте участвовали import edit_distance, import editdistance, import textdistance, from jellyfish import:
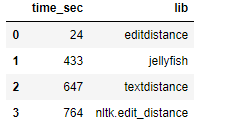
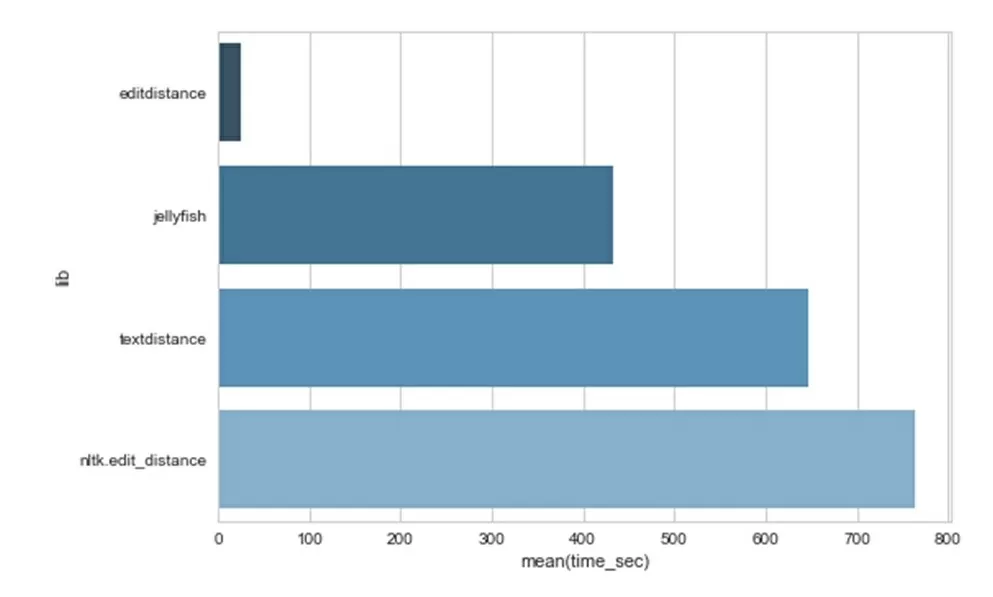
Библиотека editdistance производительнее аналогов от 18 до 31 раза.
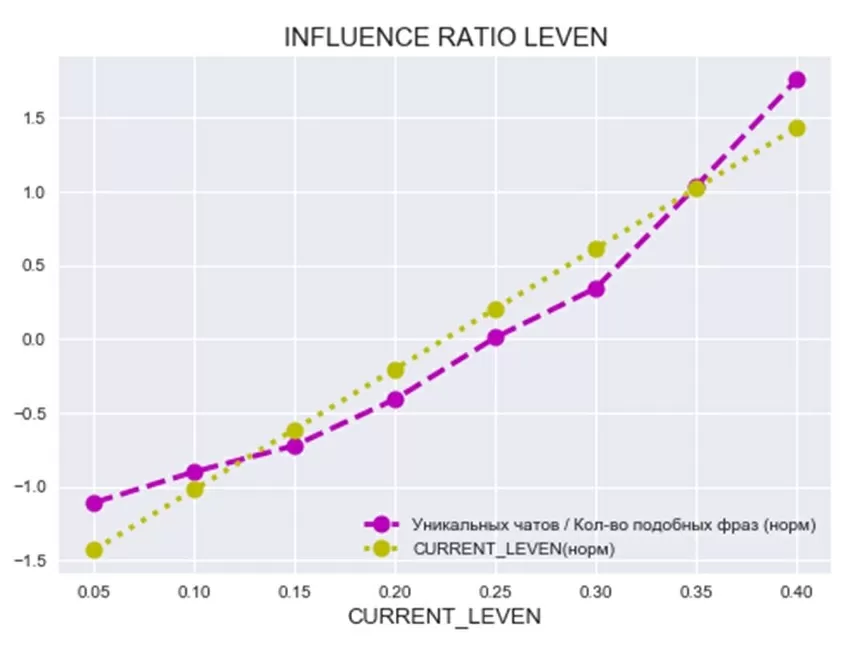
Чтобы определить допустимую схожесть текстов используем метрику CURRENT_LEVEN, которая ограничит допустимое значение отношения редакционного расстоянию двух сравниваемых текстов к длине первого текста — editdistance (text1, text2)/ длину текста(text1).
Значение параметра CURRENT_LEVEN подбирается опытным путем. Проведением итерации расчета и добавления стоп-слов. Значение зависит от средней длины сравниваемых текстов и индивидуально для каждого исследования. В моем случае рабочий CURRENT_LEVEN составил 0.25.
Анализ полученных результатов
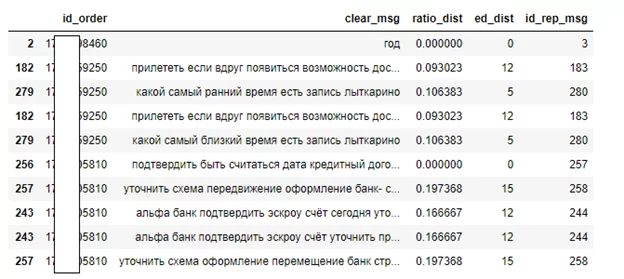
Формируется dataframe из расчетных данных:
df_rep_msg = pd.DataFrame(ls, columns=['id_order', 'clear_msg', 'clear_msg2', 'ratio_dist', 'ed_dist'])
df_rep_msg['id_rep_msg'] = df_rep_msg.reset_index()['index'] +1
df_rep_msg.head()

Разворот сообщений в строки:
df1 = df_rep_msg[['id_order','clear_msg','ratio_dist','ed_dist', 'id_rep_msg']]
df2 = df_rep_msg[['id_order','clear_msg2','ratio_dist','ed_dist', 'id_rep_msg']]
df2.columns = ['id_order','clear_msg','ratio_dist','ed_dist','id_rep_msg']
df_rep_msg = pd.concat([df1, df2], axis=0).sort_values(by=['id_order'], ascending=[True])
del df1
del df2
df_rep_msg.drop_duplicates(inplace=True)
df_rep_msg.head(10)
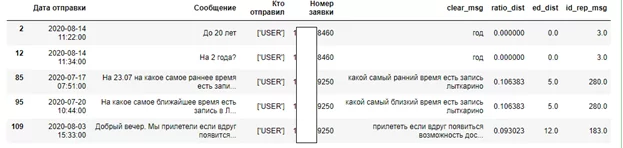
Добавляются признаки к датафрейму df_users_rep_msg
df_users_rep_msg = pd.merge(
df_users, df_rep_msg, how='left',
left_on=['clear_text','Номер заявки'],
right_on=['clear_msg','id_order']
)
df_users_rep_msg[df_users_rep_msg.clear_msg.notnull()][
['Дата отправки', 'Сообщение', 'Кто отправил', 'Номер заявки', 'clear_msg', 'ratio_dist', 'ed_dist','id_rep_msg']
].head()
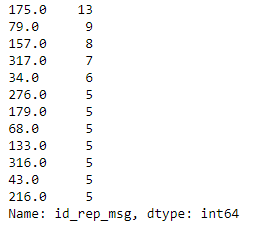
Посмотрим на сообщения, количество которых повторяются более 6 раз в одном чате
count_ser = df_users_rep_msg[df_users_rep_msg.id_rep_msg.notnull()]['id_rep_msg'].value_counts()
filt = count_ser[count_ser > 4]
filt
df_users_rep_msg[df_users_rep_msg.id_rep_msg.isin(filt.index)][['Дата отправки','Сообщение','id_order']]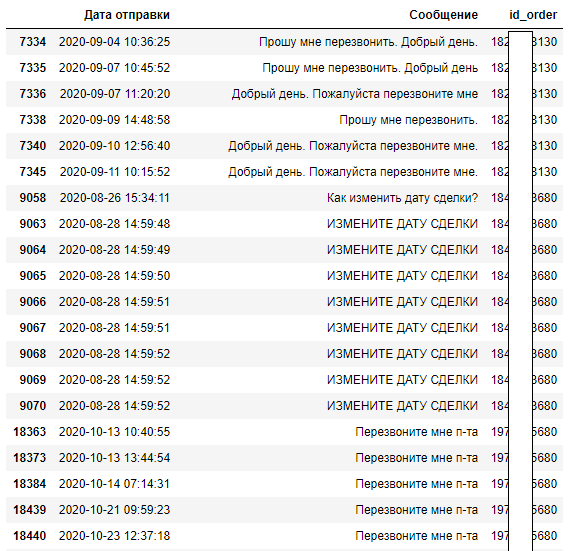
Следует уделить внимание на чаты, в которых присутствуют частотные сообщения от клиентов, как в примере выше, и выяснить причину настойчивости и удовлетворённость клиента сервисом.
Разметим основной дата фрейм
df_m = pd.merge(
df, df_users_rep_msg[df_users_rep_msg.id_rep_msg.notnull()],
how='left',
left_on = ['Дата отправки','Кто отправил', 'Номер заявки', 'Сообщение'],
right_on =['Дата отправки','Кто отправил', 'Номер заявки', 'Сообщение']
)
df_m = df_m[['Дата отправки', 'Сообщение', 'Кто отправил', 'Номер заявки','clear_msg',
'ratio_dist', 'ed_dist', 'id_rep_msg']]
df_m.loc[18206:18216]

Получим минимальный и максимальный индекс по каждому совпавшему сообщению
df_temp = df_m[df_m.id_rep_msg.notnull()][['id_rep_msg']]
df_temp['id_row'] = df_temp.index.astype('int')
df_temp.id_rep_msg = df_temp.id_rep_msg.astype('int')
index_arr = df_temp.groupby(by = 'id_rep_msg')['id_row'].agg([np.min, np.max]).values
index_arr[0:10]
>>>
array([[ 36383, 36405],
[108346, 108351],
[ 12, 43],
[ 99376, 99398],
[111233, 111235],
[121610, 121614],
[ 91234, 91252],
[ 11963, 11970],
[ 7103, 7107],
[ 53010, 53016]], dtype=int64)
df_m.loc[index_arr[194][0]:index_arr[194][1]]
В примере ниже видно, как обращение перехватил бот/автоматизированная система, клиент не игнорирован
df_m.loc[index_arr[194][0]:index_arr[194][1]]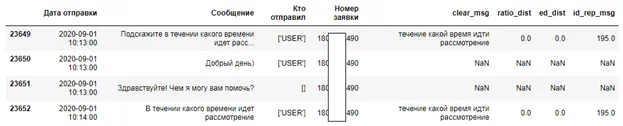
Проверяем остальные случаи
#Проверим остальные случаи
results = {'Ответ_получен':0, 'Ответ_проигнорирован':0, 'Всего_групп_повторных_сообщений':0}
results['Всего_групп_повторных_сообщений'] = len(index_arr)
for i in range(len(index_arr)):
if len(set(df_m.loc[index_arr[i][0]:index_arr[i][1]]['Кто отправил'].tolist()) - set(["['USER']"])) > 0:
results['Ответ_получен'] += 1
elif len(set(df_m.loc[index_arr[i][0]:index_arr[i][1]]['Кто отправил'].tolist()) - set(["['USER']"])) == 0:
results['Ответ_проигнорирован'] += 1
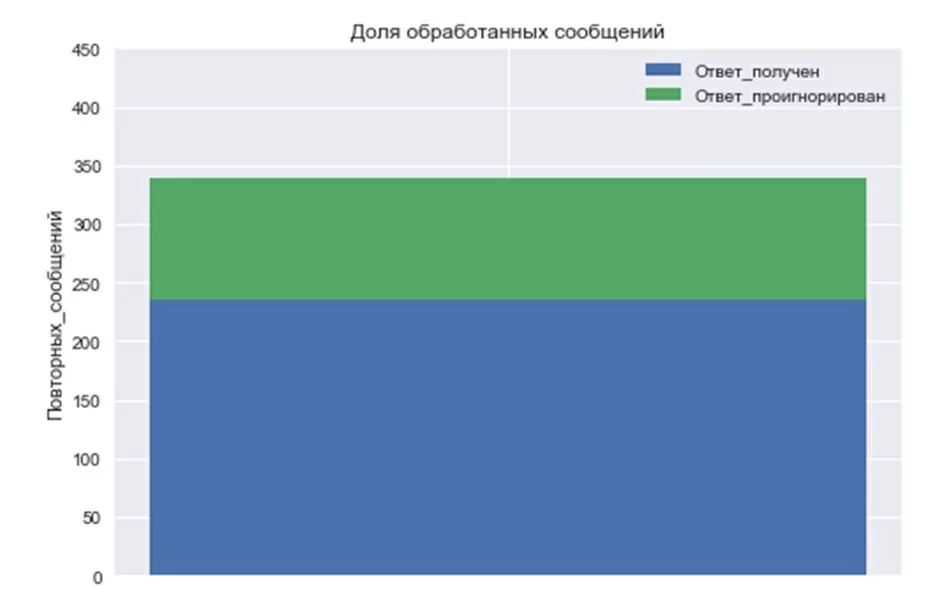
print('Доля проигнорированных сообщений:', round(100*(results['Ответ_проигнорирован']/results['Всего_групп_повторных_сообщений']), 2), '%')
results

Количество обработанных сообщений:
N = 1
anw_yes = (236)
anw_no = (103)
ind = np.arange(N)
width = 0.35
p1 = plt.bar(ind, anw_yes, width)
p2 = plt.bar(ind, anw_no, width, bottom=anw_yes)
plt.ylabel('Повторных_сообщений')
plt.title('Доля обработанных сообщений')
plt.xticks(ind, (''))
plt.yticks(np.arange(0, 500, 50))
plt.legend((p1[0], p2[0]), ('Ответ_получен', 'Ответ_проигнорирован'))
plt.show()
Заключение
С помощью NLP модели, построенной на измерении редакционного расстояния по Левенштейну, удалось сократить кол-во проверяемых чатов с 5406 ед. до 339 ед. Из них определить высоко-рисковые чаты — 103 ед. Определить и использовать в расчетах высокопроизводительную библиотеку для расчета дистанции редактирования между текстами, позволяющую масштабировать проверку на большие объемы информации.