/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Alpha-алгоритм — первый в технологии анализа процессов, который позволял находить так называемые Workflow nets из логов процессов. Алгоритм был разработан в 2013 году самим основателем методологии Process Mining профессором Will M.P. van der Aalst.
Что такое Workflow nets (далее WF)– это сеть, построенная на основе сетей Petri. Про них я рассказывать подробно не буду, о них можно почитать здесь (вставить ссылку на википедию). Для нас важно одно – WF на основе сетей Petri позволяет представлять и в дальнейшем анализировать рабочие процессы.
Отличительными чертами WF являются:
- Четкое начало. (Уникальное действие, которое только запускает все цепочки действий)
- Четкий конец (Уникальное действие, которое только заканчивает все цепочки действий)
- Каждое отдельное действие находится между п.1. и п.2.
Давайте посмотрим на пару примеров:
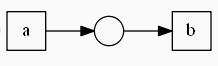
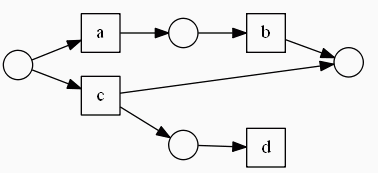
Данные схемы не являются WF. Почему? В первом случае у нас отсутствует начало и конец цепочки (они обозначаются кругом). Во втором случае действие d не имеет окончания.
Ниже я привел пример правильной WF сети – есть начало и конец, а все действия расположены между ними и завершены.
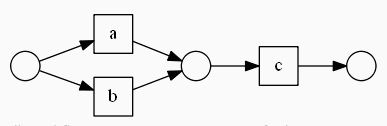
Немного прояснив, что такое WF, переходим к работе alpha алгоритма:
Для того, чтобы получить WF с использованием alpha алгоритма, нам потребуется навести порядок в нашем логе. Для этого мы определим следующие отношениями между переходами в логе событий (в дальнейшем они понадобятся для построения модели):
- Прямая последовательность.
Событие A > Событие B.
В реальном логе событий это выглядело бы так:

- Причинно-следственная связь.
Событие A → Событие B.
Означает, что в логе событий есть такие переходы

Но нет таких:

Следовательно на схеме мы ставим символ
- Параллельные события.
В логе встречаются оба перехода Событие A → Событие B и Событие B → Событие A.
- Отсутствие последовательности.
Событие A # Событие B и наоборот. Эти события не встречаются в логе.
Общий датасет из всех переходов называется множество L.
Давайте разберем небольшой пример. Ниже приведен лог, состоящий из трех случаев.
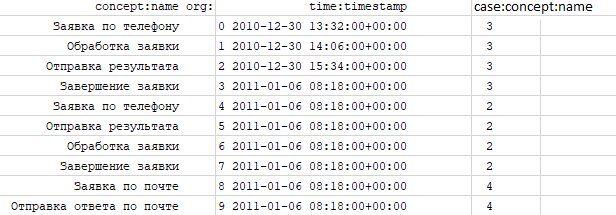
Напишем связи из нашего лога, которые используются в alpha алгоритме:
- Заявка по телефону > Обработка заявки,
Заявка по телефону > Отправка результата,
Обработка заявки > Отправка результата,
Обработка заявки > Завершение заявки,
Отправка результата > Обработка заявки,
Отправка результата > Завершение заявки,
Заявка по почте > Отправка ответа по почте
- Заявка по телефону → Обработка заявки,
Заявка по телефону → Отправка результата,
Обработка заявки → Завершение заявки,
Отправка результата → Завершение заявки,
Отправка результата→ Завершение заявки,
Заявка по почте → Отправка ответа по почте
- Обработка заявки || Отправка результата
На основании полученных отношений, рисуем WF.
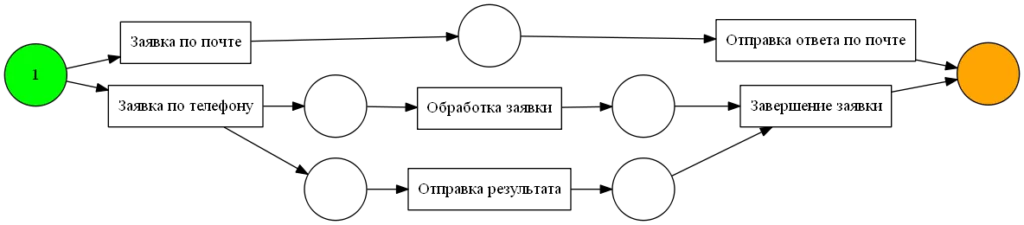
Полученная модель охватывает все действия нашего лога и ее легко анализировать.
Ограничения работы alpha алгоритма.
Если в вашем логе встречаются одинарные или двойные петли (повторения действий), алгоритм неверно трактует и может генерировать модель, которая отличается от ожидаемой. Вернемся к нашему логу ранее и добавим в него повторения:
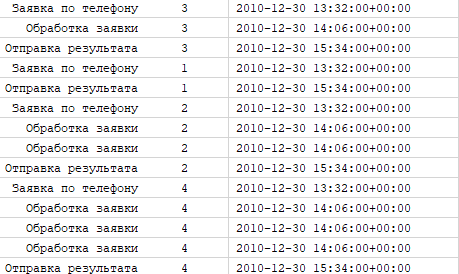
Ожидаемая модель будет выглядеть так:
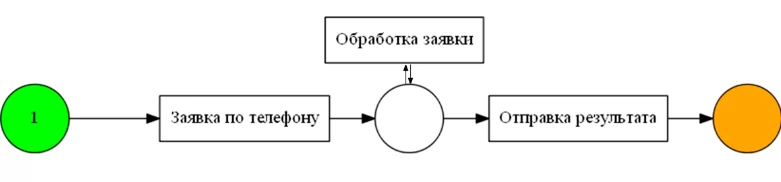
Но alpha алгоритм выдаст нам совершенно другую картину:

В чем причина? Действие «Обработка заявки» не имеет начала и конца. В процессе генерации модели создается множество A ( где есть все начала ) и множество B ( окончания процессов ). Так как при многократных повторениях, у нас пропадают данные множества, алгоритм не может их найти. Соответственно данное действие выпадает из общей модели.
Та же ситуация происходит с двумя повторяющимися действиями подряд. Alpha алгоритм оставит только одно из них, а второе выпадет и мы не сможем интерпретировать модель.
Как можно решить данную проблему? Нужно максимально учитывать особенности той системы, которую вы анализируете. Если ваша система пишет в лог не только основные моменты, но и действия, которые генерируются автоматически ( например, в случаях рукописного ввода, система может каждые 5 секунд делать автосохранение и записывать это в лог), то есть смысл объединять эти действия в один элемент.
Спасибо за внимание!