/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
При работе с клиентами очень важно понимать, какими из предоставляемых услуг они недовольны. Для этого эффективнее всего работать с отзывами клиентов. В качестве примера рассмотрим отзывы постояльцев гостиницы. Однако понять, на что жалуются чаще всего не так просто. На практике вы встретите, как минимум, две сложности:
- Вы понятия не имеете, что искать. Понятно, что несколько постояльцев могут жаловаться на один и тот же недостаток: неудобную кровать, неработающее освещение, маленькую ванную. Но вы не знаете ни сколько видов этих недостатков, ни какие они конкретно.
- Данных может быть очень много. Выгрузив отзывы хотя бы за один месяц, вы можете получить несколько тысяч текстов.
Итак, у вас на руках тысячи текстов, которые вам нужно сгруппировать по темам. Понятно, что обрабатывать этот объем регулярными выражениями неэффективно, ведь вы даже не знаете, что вы ищете. Просматривать их вручную, стараясь выделить темы, тоже не вариант.
Что же делать? Именно для решения подобных задач и созданы алгоритмы тематического моделирования. Основополагающий алгоритм тематического моделирования – LSA (сокр. от Latent Semantic Analysis). Наряду с ним применяются его вероятностные модификации — PLSA (сокр. от Probabilistic Latent Semantic Analysis) и LDA (от англ. Latent Dirichlet Allocation).
Данные алгоритмы базируются на следующих предположениях:
- Любой текст представляет собой смесь нескольких тем
- Любая тема представляет собой набор соответствующих ей слов
В этих предположениях можно считать, что содержимое текста зависит от набора нескольких переменных – тем. Проблема в том, что нам эти темы неизвестны, поэтому их называют «скрытыми переменным». Задача алгоритмов тематического моделирования: выявление этих переменных. В научной литературе принято для обозначения одного текста использовать термин «документ». Так и поступим в этой статье.
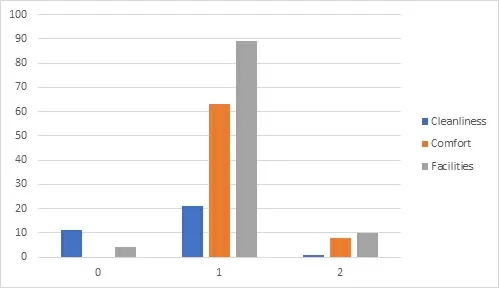
Рассмотрим применение алгоритмов к отзывам на гостиницу. Модельная выборка содержит 207 отзывов, размеченных следующим образом:
| text | sentiment | topic |
| The rooms are extremely small, practically only a bed. | negative | Comfort |
| Room safe did not work. | negative | Facilities |
| Mattress very comfortable. | positive | Comfort |
| Very uncomfortable, thin mattress, with plastic cover that rustles every time you move. | negative | Comfort |
| No bathroom in room | negative | Facilities |
| The bed was soooo comfy. | positive | Comfort |
| someone must have been smoking in the room next door. | negative | Cleanliness |
В первом столбце собран сам текст отзыва – это документ, во втором – тональность отзыва. В третьем – одна из трёх заранее определенных тем: Cleanliness, Comfort и Facilities.
Считаем набор данных с помощью pandas и приведем столбец с текстом отзывов к строковому типу, удалив из него знаки табуляции и новой строки:
df = pd.read_csv("reviews.csv")
df.text = df.text.apply(lambda x: str(x))
df.text = df.text.apply(lambda x: x.replace('\n',' ')).apply(lambda x: x.replace('\t',' '))LSA
Для начала, произведем подготовку данных к анализу, удалив из отзывов стоп-слова. Это можно сделать с использованием nltk.stopwords из модуля nltk для Python:
def preprocessing(text):
re.sub('([0-9]+)', ' \\1 ', text)
regex.sub('', text)
# pattern = u'(?ui)\\b\\w*[а-яё]+\\w*\\b [\d.,] + |[A-Z][.A-Z]+\b\.*|\w+|\S'
pattern = u' [\d.,] + |[A-Z][.A-Z]+\b\.*|\w+|\S'
tokenizer = RegexpTokenizer(pattern)
text=tokenizer.tokenize(text)
text = [token for token in text if token not in russian_stopwords]
text = [token for token in text if token not in english_stopwords]
text = [token for token in text if token not in string.punctuation]
# text = [token for token in text if re.search('^[0-9]+$', token) == None]
return ' '.join(text)Применим описанную функцию предобработки к отзывам:
actions_df = pd.DataFrame(df['text'].apply(lambda x: str(x)))
actions_df.text = actions_df.text.apply(lambda x: preprocessing(x))
Обработанные отзывы преобразуем в TF-IDF матрицу:
corpus = actions_df['text']
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)<207x582 sparse matrix of type '<class 'numpy.float64'>'
with 1157 stored elements in Compressed Sparse Row format>Как видно, TF-IDF векторизация превратила наши документ в 582-мерные вектора из чисел. Сократим размерность пространства до 100, используя SVD – разложение.
SVD = TruncatedSVD(100)
X_redused = sparse.csr_matrix(SVD.fit_transform(X))Получим матрицу:
<207x100 sparse matrix of type '<class 'numpy.float64'>'
with 20700 stored elements in Compressed Sparse Row format>Как видно, в ней вектора стали уже 100-мерными. Теперь к этой матрице можно применить алгоритмы кластеризации. Для демонстрации были выбраны алгоритмы DBSCAN и K-means. Для выбора параметров кластеризации алгоритма DBSCAN использовался цикл, в котором параметры изменялись с небольшим шагом. Результаты итераций собраны в словарь count_of_clusters. Ключом в нём является значение параметра eps, значением – количество отзывов в образовавшихся кластерах.
#applyin DBSCAN clusterisation
step_list2 = [i*0.001 for i in range(1,100)]
step_list1 = [i*0.1 for i in range(1,12)]
count_of_clusters = {}
for i in step_list1:
for j in step_list2:
clustering = DBSCAN(eps=i+j, min_samples=5, metric='euclidean', algorithm= 'brute' ).fit(X_redused)
count_of_clusters.update({i+j: np.unique(clustering.labels_, return_counts= True)})
count_of_clustersНиже приведена часть словаря count_of_clusters:
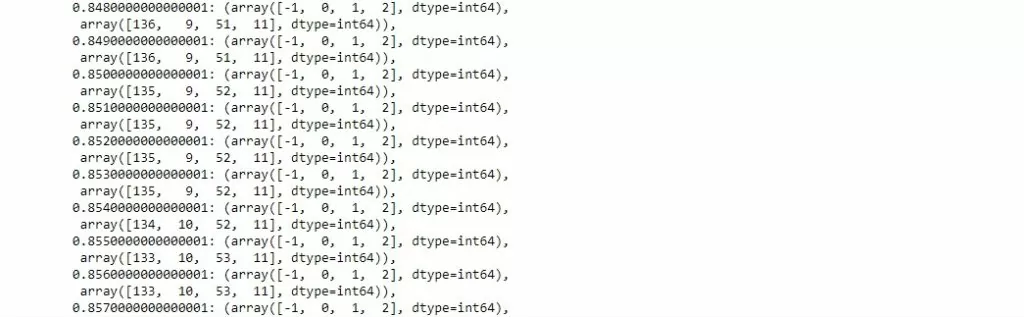
После этого мы выбираем необходимое нам значение eps, а количество кластеров DBSCAN установит автоматически. Для K-means было выбрано 3 кластера:
#selected DBSCAN
clustering = DBSCAN(eps=0.911, min_samples=5, metric='euclidean', algorithm= 'brute' ).fit(X_redused)
#K-Means
k_means_clustering = KMeans(n_clusters=3, random_state=0).fit(X_redused)
df['DBSCAN_CLUSTER']=clustering.labels_
df['KMeans_CLUSTER'] = k_means_clustering.labels_
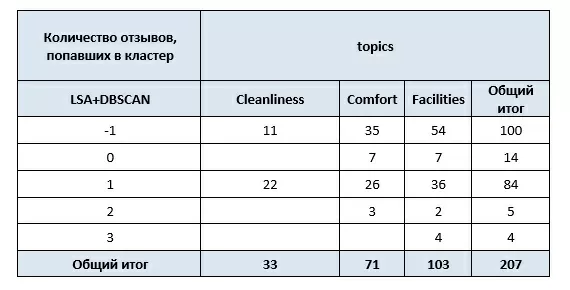
df.to_excel("TF_IDF+clustered_data.xlsx")Результаты кластеризации отзывов с помощью DBSCAN:
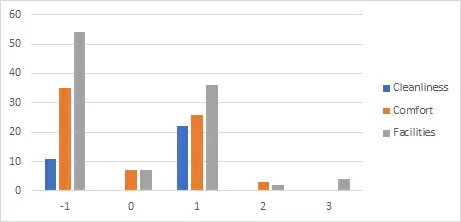
Графически можно представить, как:
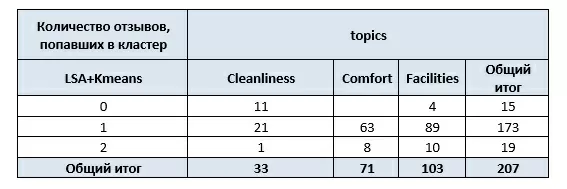
Результаты работы алгоритма K-means:
И их графическое представление:
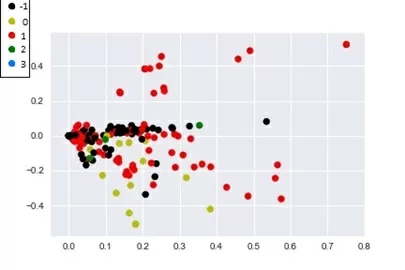
Здесь мы наблюдаем интересный эффект: можно было бы ожидать, что алгоритм LSA и кластеризация разобьют наши отзывы на три темы: Cleanliness, Comfort и Facilities. Но это не так. В начале статьи упоминалось, что тема документа является «скрытой» переменной, поэтому она определяется не как одно из трёх значений поля topics, а как их смесь.
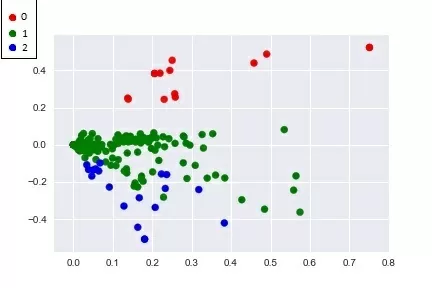
Для того, чтобы наглядно посмотреть на то, как кластеризация разбила документы на группы по темам, сократим размерность векторов до двух. Теперь результаты работы LSA и кластеризации можно визуализировать. Каждая точка на полученных графиках – один документ.
Кластеризация DBSCAN:
Кластеризация K-means:
По ссылке Вы найдёте очень наглядную анимацию того, как работает LSA при кластеризации документов по темам. Для этого сначала выберите Order: by document similarity, а затем Order: by term similarity.
LDA
LDA является вероятностной модификацией LSA и опирается на следующие предположения:
- В данном документе doc тема z присутствует с вероятностью;
- Вероятность того, что из данной темы z будет выбрано слово w равна P(w|z).
В таких предположениях документ генерируется следующим образом:
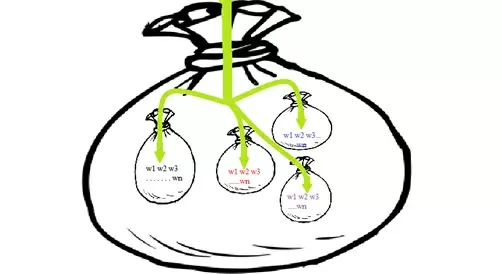
Нам дан большой мешок, в котором лежат темы – это мешки поменьше. Внутри каждого мешка-темы лежат слова. Мы запускаем руку в большой мешок и с вероятностью вытаскиваем из него мешок-тему, затем из этого мешка-темы с вероятностью P(w|z) вытаскиваем слово. По итогу получаем документ типа:
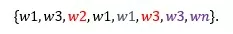
Исходя из такого принципа построения документа, вероятность встретить слово W в документе D вычисляется как:
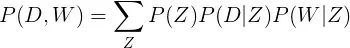
P(Z), P(D/Z) и P(W/Z) необходимо подобрать. В PLSA предполагается, что эти распределения являются полиномиальными, а в LDA — что они имеют априори распределение Дирихле. Отсюда и название.
Рассмотрим теперь, как алгоритм LDA кластеризует наши отзывы. Проведя векторизацию на обработанных данных, получили следующее:
Количество уникальных токенов: 185
Количество документов: 207То есть, на 207 документов выделена 185 уникальных слов, смеси из которых и будут характеризовать тему. Обучим модель LDA из модуля genism для Python на поиск 36 тем.
from gensim.models.ldamulticore import LdaMulticore
model=LdaMulticore(corpus=corpus, id2word=dictionary, num_topics=36)
model.show_topics()По итогу, с помощью визуализатора, получим следующую картину:
import pyLDAvis.gensim
import gensim
pyLDAvis.enable_notebook()
data = pyLDAvis.gensim.prepare(model, corpus, dictionary)
data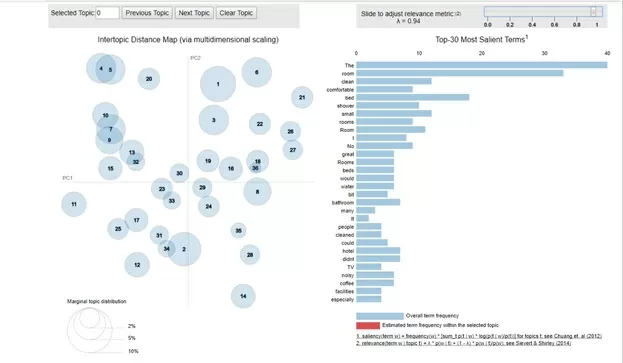
Из рисунка видно, что кластеры распределены достаточно обособлено. Однако, некоторые из них имеют взаимные пересечения. Рассмотрим, к примеру, темы 4 и 5.
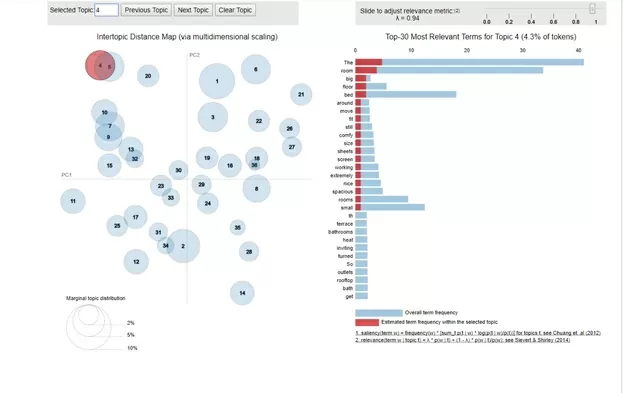
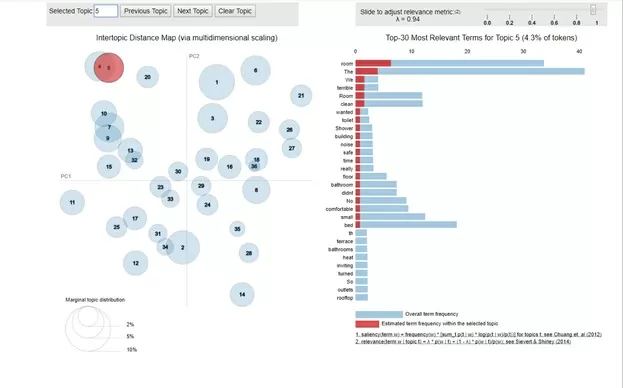
На шкале в правой части иллюстраций показано, какие слова характеризуют эти темы. И видно, что набор характеризующих слов и их «важность» для темы довольно близки между собой. Это говорит о том, что, возможно, стоит выбрать меньшее количество тем для обучения алгоритма. В этом случае темы 4 и 5 будут объединены в одну. Для сравнения рассмотрим тему, которая не имеет с 4 и 5 ничего общего. Например, тему 20:
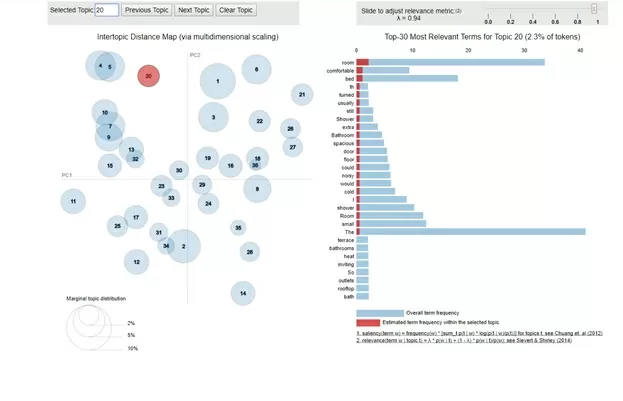
Тут видно, что и определяющие слова, и их «важность» для темы отличаются от тем 4 и 5 куда более значительно.
Уменьшим количество тем, чтобы исключить пересекающиеся кластеры, например, до 10:
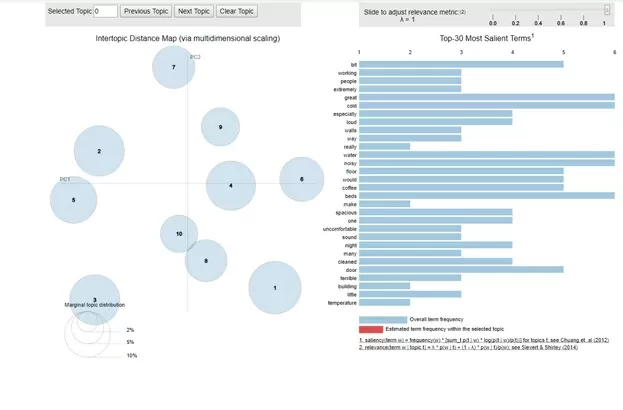
Тут видно, что темы, определённые LDA, являются обособленными. Рассмотрим, какими словами они характеризуются. Для примера рассмотрим тему 2:
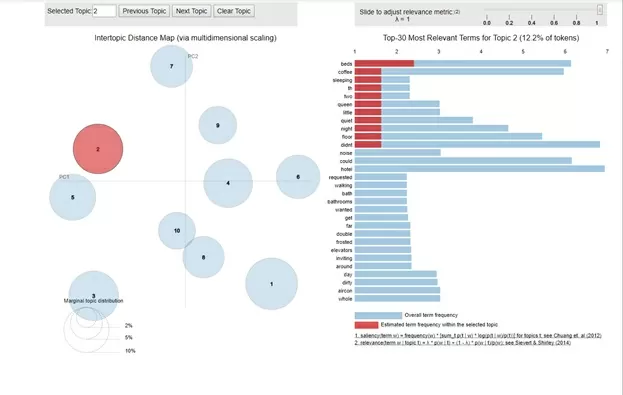
Теперь рассмотрим то, как именно LDA определяет тематический состав документа: Если мы рассмотрим результаты, которые алгоритм выдаст на отзыве ‘Room safe did not work.’, получим вывод вида:
(3, 0.69997957503884844)
(9, 0.03334203079939373)
(5, 0.03333927606613573)
(2, 0.03333911500939606)
(1, 0.03333333395483537)
(7, 0.03333333394142473)
(6, 0.03333333388004364)
(0, 0.03333333382171126)
(8, 0.03333333380035912)
(4, 0.03333333368785165)В этом списке первым значением является тема, определенная LDA, а вторым указана вероятность того, что эта тема присутствует в отзыве. То есть, алгоритм LDA представляет документ в виде «смеси» из тем с указанием их вероятностей. Это как раз иллюстрирует пример с мешком, описанный ранее.
Будем считать темой отзыва ту, вероятность которой самая большая:
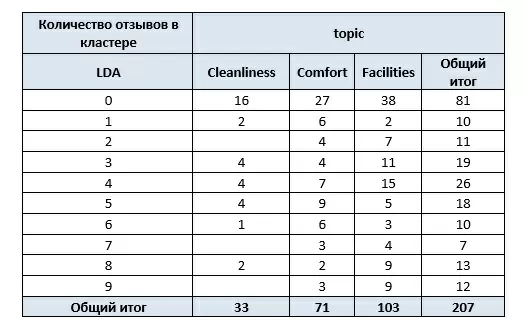
Или графически:
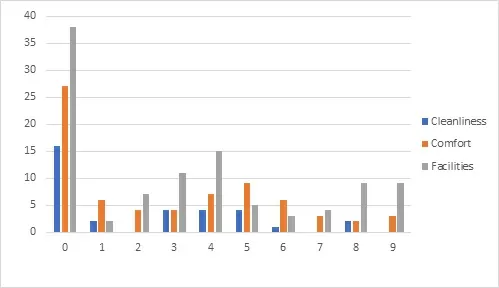
На наглядном примере мы увидели работу алгоритмов тематического моделирования. А разметка отзывов по полю topic позволила показать, почему «скрытые» переменные так называются.
Эти отзывы – модельный пример, на практике количество данных будет намного больше, а разметить их практических невозможно. В этом случае алгоритмы тематического моделирования проявят себя наилучшим образом и помогут эффективно справиться с задачей. Применив любой из них, вы получите подгруппы отзывов, собранные в кластеры по темам. Для того, чтобы понять, какой именно теме посвящены отзывы в группе, останется лишь посмотреть на набор наиболее характерных слов для неё.