/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Задача
В условиях значительного потока информации, в том числе и текстовой, появляется необходимость фильтровать ее автоматически, с помощью алгоритмов. Одним из возможных подходов к выделению смысла текста и оценке его релевантности является задача извлечения ключевых слов. Идея заключается в том, чтобы выделить слова или фразы, которые являются наиболее важными для всего текста и передают его основную тематику.
Алгоритмы без учителя обладают преимуществом в условиях большого объема данных – нет необходимости в разметке данных, которая для данной задачи является достаточно трудоемкой. Дополнительной характеристикой методов, о которых пойдет речь, является отсутствие моделей. Все 3 метода основаны на эвристиках, которые заданы заранее, а не обучаются. Это позволяет обрабатывать каждый текст отдельно и не требует большой выборки текстов.
Rake
Основной идеей алгоритма является то, что ключевые слова зачастую находятся в окружении стоп-слов и пунктуации.
| Стоп-словами называют слова, которые сами по себе не несут высокой смысловой нагрузки и используются совместно с другими словами |
Обычно в множество стоп-слов входят предлоги, союзы и другие функциональные части речи. В большинстве приложений интеллектуального текстового анализа стоп-слова считаются незначимыми и убираются на этапе предобработки, однако в данном методе играют важную роль.
Стоп-слова и пунктуация расценивается как разделители фраз – текст разбивается по этим элементам на фразы кандидаты. Далее фразы-кандидаты ранжируются по метрике deg(w)/freq(w) и выбираются k кандидатов с наибольшим значением метрики.
Метрика основана на следующей логике:
- freq(w) – Частота слова в тексте, поощряет часто встречающиеся слова
- deg(w) — Определяется как сумма совместных появлений других слов с этим словом. Совместным появлением считается появление в одной фразе. Данная метрика поощряет слова, которые часто встречаются в длинных кандидатах
- freq(w)/deg(w) – Поощряет слова, которые появляются в основном в длинных кандидатах
YAKE!
Этот метод похож по смыслу на Rake, однако была убрана идея о выделении фраз на основе стоп-слов. В данном методе используется стандартная для текстового анализа методика выделения слов и фраз с помощью токенизации. Фактически такая методика позволяет проверить все сочетания слов на их важность, а не только разделенные стоп-словами. YAKE! использует более сложную метрику, чем Rake – она собирается из 5 отдельных метрик.
Casing
Метрика Casing основана на идее о том, что ключевые слова зачастую могут быть названиями или аббревиатурами. Она измеряет количество раз, когда слово в тексте встречается с большой буквы или является аббревиатурой (написано полностью большими буквами).
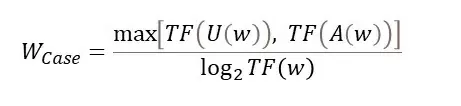
Где:
- TF(U(w)) – Количество раз, когда слово начинается с большой буквы
- TF(A(w)) – Количество раз, когда слово отмечается алгоритмом, как аббревиатура (Состоит из больших букв)
- TF(w) – Общая частота слова
Word Position
Авторы утверждают, что ключевые слова чаще стоят в начале текста. Из-за этого вводится метрика Word Position, которая учитывает положение слова относительно других.
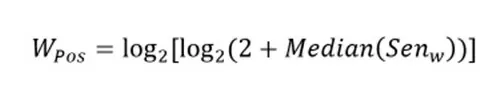
Где:
- Senw — множество позиций слова в документе
Word Frequency
Как и в Rake учитывается частота слова. В данном случае частота слова нормируется с учетом среднего и стандартного отклонения частоты:
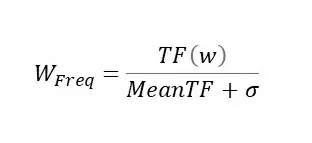
Где:
- TF(w) – Частота слова в тексте
Word Relatedness to Context
Авторы утверждают, что данная метрика способна оценивать, насколько слово похоже на стоп-слово – насколько оно важно для контекста. Метрика использует количество слов, появляющихся слева и справа от слова-кандидата
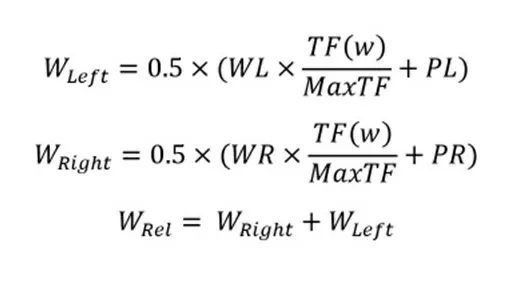
Где:
- WL – отношение количества слов слева от кандидата к количеству всех слов, которые появляются вместе с ним
- WR – отношение количества слов справа от кандидата к количеству всех слов, которые появляются вместе с ним
- PL – Отношение количества разных слов, которые появляются слева от кандидата к MaxTF
- PR — Отношение количества разных слов, которые появляются справа от кандидата к MaxTF
Утверждается, что стоп-слова имеют высокое значение метрики Wrel
DifSentence
Эта метрика учитывает количество предложений, в которых используется слово-кандидат.
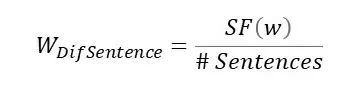
Где:
- SF(w) – Частота появления слова в предложениях
- # Sentences – Количество предложений в тексте
Итоговая метрика
Итоговая метрика составляется из описанных выше метрик.
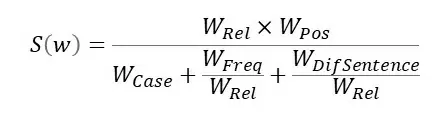
Далее происходит сортировка ключевых слов по этой метрике и выбирается k наиболее значимых.
TextRank
Метод TextRank наиболее сильно отличается от двух предыдущих. Он использует идею, что любой текст можно представить в виде графа, где слова являются вершинами, а связи между ними – ребрами графа. После переведения текста в графовое представление используется классическая метрика важности вершин графа PageRank.
Построение графа
Для построения графа вокруг каждого слова берется контекст – берутся все слова, которые находятся на расстоянии n-слов от главного. Например, для контекста размера 2 берутся два слова слева и два слова справа от текущего. Все слова в контексте текущего связываются с ним ребрами графа.
PageRank
Рассмотрим метрику, которая используется для выделения важных вершин на графе.
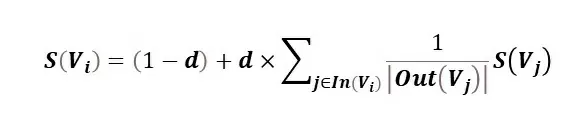
Где:

Важность инициализируется случайными числами и потом итеративно сходится к правильным значениям. Таким образом, важность слова определяется связью с другими важными словами.
Python-реализация алгоритмов
Для демонстрации работы алгоритмов используем текст про алгоритм Евклида из Википедии.
Rake
!pip install nlp-rake
!pip install nltk
from nlp_rake import Rake
import nltk
from nltk.corpus import stopwords
nltk.download ("stopwords")
stops = list(set(stopwords.words("russian")))
rake = Rake (stopwords = stops, max_words = 3)
rake.apply(text) [:10]
[('который впервые описал', 9.0),
('старейших численных алгоритмов', 9.0),
('формирует новую пару', 9.0),
('другие математические структуры', 9.0),
('открытым ключом rsa', 9.0),
('построение непрерывных дробей', 9.0),
('сумме четырех квадратов', 9.0),
('евклид предложил алгоритм', 8.75),
('позже алгоритм евклида', 8.75),
('также алгоритм используется', 8.75)]YAKE!
!pip install yake
import yake
extractor = yake.KeywordExtractor (
lan = "ru", # язык
n = 3, # максимальное количество слов в фразе
dedupLim = 0.3, # порог похожести слов
top = 10 # количество ключевых слов
)
extractor.extract_keywords(text)
[('нахождения наибольшего общего', 0.007730938617944613),
('алгоритм евклида', 0.02890147800046243),
('меры двух отрезков', 0.03272710509306345),
('общего делителя', 0.037949396773603226),
('эффективный алгоритм', 0.08642709208765043),
('целых чисел', 0.09043705959596256),
('III век', 0.09429235043018239),
('евклида применяется', 0.14724083794565102),
('делителя двух целых', 0.15952161600757106),
('честь греческого математика', 0.1598415740734964)]TextRank
!pip install summa
from summa import keywords
text_clean = ""
# уберем стоп-слова
for i in text.split():
if i not in stops:
text_clean += i + " "
keywords.keywords (text_clean, language = "russian").split("\n")
['алгоритм'
'алгоритмов',
'алгоритма',
'числом',
'евклида',
'евклид',
'такого',
'такие',
'меньшего числа',
'паре',
'пары',
'общей',
'таких теорема',
'число наибольший общий делитель',
'пару которая',
'целые',
'это',
'в',
'наибольшего общего делителя двух целых чисел',
'полиномы',
'основным',
'основная',
'который',
'век',
'математических',
'математические',
'является',
'веке обобщен другие',
'меньшим',
'теорем',
'теории',
'современной',]Вывод
Все три алгоритма решают одну и ту же задачу с разных сторон и с использованием разной логики. Результаты работы алгоритмов из-за этого отличаются. Нельзя однозначно сказать, какой из них лучше решает конкретную задачу. На отдельной задаче имеет смысл тестировать качество каждого из алгоритмов и делать выбор исходя из этого.