/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
17:45, 15 минут до завершения рабочего дня…
Олег: Отлично! И я почти закончил запланированные на сегодня задачи.
тук-тук-тук
Олег: Да-да!
Виталий: Привет! Олег, у нас тут очень интересная задачка…
Олег: Привет! Знаю я ваши интересные задачки под конец рабочего дня!
Виталий: Да тебе дел-то на 5-10 минут, а мы уже пол дня в ручную ковыряем и еще половину не сделали, а тема интересная, горящая, завтра уже нужны результаты, а нам бы их еще «покрутить»…
Олег: Ладно, давайте, рассказывайте, что там у вас?
Виталий: Смотри, у нас есть несколько файлов журналов- банкоматов…
Итак, недавняя практическая, рабочая задача.
Виталий: Мы анализируем сессии банкоматов, и нам нужно из журналов получить время начала клиентской сессии. Только вот мы привыкли работать с таблицами Excel, а тут нам прислали файлы, которые даже не понятно, как открыть…
Олег: Сколько у вас файлов?
Виталий: Четыре!
Олег: Ну давайте их сюда, мушкетёры! Так, похоже, что тут нужно немного теории…
Чтобы операционная система (ОС) могла отличать файлы по видам и для каждого вида запускать свою программу (это когда вы совершаете двойной клик по пиктограмме файла), в имени файла имеется так называемое расширение, символы в самом хвосте имени, после точки. Например, .txt – текстовые файлы, .xls – файлы с таблицами MS Excel, mp3 – музыкальные файлы и т.д. Именно исходя из этих символов, ОС принимает решение: какое приложение запускать. А если ни одно приложение не сопоставлено расширению файла, то ОС дает возможность пользователю выбрать приложение самостоятельно. Последнее справедливо для ОС семейства Windows. Следует отметить, что расширение файла может не соответствовать его содержанию.
Виталий: Это мы знаем, конечно, но только тут у файла расширение PRJ! Нам оно ни о чём не говорит!
Олег: Мне тоже, если честно. Но мы можем открыть этот файл любым текстовым редактором и попробовать прочитать его.
Виталий: Что тут сказать…

Олег: Думаю, ещё немного теории нам не повредит…
Файл – это область памяти на диске, имеющая имя и длину. Это старенькое определение, которое я помню со школьного курса Информатики. Но сейчас его, конечно же, нужно формулировать по-другому, т.к. с тех пор аппаратная часть сильно расширилась – появились и флэшки, и облака, да и файл в оперативной памяти давно не удивляет программиста. Но для решения задачи все это лишнее. Главное понимать, что файл – это область памяти на диске, имеющая имя и длину. А в файле хранятся данные – последовательно записанные числа, как если бы Вы взяли листик, написали на нем «Мой файл» и со следующей строки написали все, что угодно. В таком случае можно было бы говорить, что это абстрактный файл. Все компьютерные файлы состоят исключительно из чисел. Ничего другого там нет и быть не может.
Виталий: Только числа? Ведь там есть текст, изображение, таблицы, музыка и т.д., и т.п.
Олег: Все верно, все это там действительно есть. Но все это не более чем абстракция. А реально в файле всегда хранятся только числа, но программы могут представлять числа в виде текста, электронных таблиц, графических изображений, музыки, видеоряда и т.д. Такие вот они умные, эти программы, ну прям теория ограничений Голдратта!
Виталий: И как нам это поможет?
Олег: А мы будем считать, что если содержимое файла читается, значит, он текстовый (на самом деле это не всегда справедливо, но в преобладающем большинстве случаев работает, поэтому сделаем допущение и будем считать, что все именно так).
То есть программа может преобразовать хранящиеся в нем числа в текст и отобразить его. Открою его функцией просмотра Winrar, хотя можно использовать любую другую программу, например, FAR Manager, Total Commander, Notepad, WordPad, Word и т.д.

Итак… открываем и видим текст! Значит, файл текстовый.
Виталий: Отлично! Нужные нам строки содержат следующий текст: «НАЧАЛО СЕССИИ: ДД.ММ.ГГГГ ЧЧ:ММ:СС». На картинке ее можно видеть четвертой сверху. Как думаешь, что использовать для работы с ними?
Олег: Можно, конечно, использовать тяжёлую артиллерию! Запустить редактор кода, а дальше по знакомому сценарию: создать новый проект, написать пару сотен строк кода и решение готово! Но это… палить пушкой по воробьям! Всё-таки не хочется забивать гвозди микроскопом…
Виталий: Может Excel? Всё-таки весьма удобный инструмент: есть поддержка формул и макросов, функционал по фильтрации и сортировке данных, мастер импорта текстовых файлов…
Олег: Ну и реклама, аж купить захотелось! Тогда я переименовываю файл, меняю ему расширение на TXT, запускаю MS Excel и перетаскиваю пиктограмму (картинку) файла, не отпуская кнопки, в область таблицы MS Excel, после чего отпускаю кнопку. Это функция называется Drag&Drop. Весьма удобная, кстати говоря, функция, которая в переводе с английского означает – тащи и бросай. Многие ей пользуются, например, когда копируют файлы или переставляют слова в тексте, но мало кто использует её для открытия файлов приложениями. А между тем данная функция, встроена во многие приложения ОС Windows, поэтому всем рекомендую!
Виталий: Ну и реклама, аж…
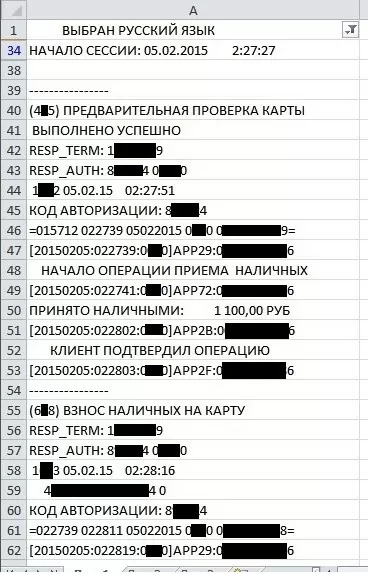
Олег: Ладно-ладно, 1:1! Ага, в итоге MS Excel загрузил данные из файла и разместил каждую строчку в отдельной ячейке столбца «A». Отлично, теперь нужно заняться их обработкой.
Данных довольно много, порядка 200 тыс. строк. Поэтому нужно их отфильтровать:
- Выделяем первую строку.
- В ленточном меню выбираем вкладку «данные» и жмем на кнопку «фильтр».
- Задаем текстовый фильтр «Начинается с …» для столбца «А», в котором указываем «НАЧАЛО СЕССИИ:» — я скопировал эту строку прям из текстового редактора, но можно набрать её и с клавиатуры.
Ну вот, данные отфильтрованы, все вроде бы нормально. Хотя подождите-ка …
Как-то уж очень странно сработал фильтр! Он выбрал первую попавшуюся ему строку, которая содержала «НАЧАЛО СЕССИИ:», а далее ничего фильтровать не стал и оставил все как есть!
На рисунке видно, что со 2 по 33 строки отсутствуют – сработал фильтр, далее есть строка 34, содержащая «НАЧАЛО СЕССИИ:», далее строки 35 — 37 отсутствуют – тоже сработал фильтр. А далее, с 38 строки фильтр не сработал.
Чтобы разобраться, в чем проблема, нужно взглянуть на 38 строку. Именно с нее фильтр перестает работать, поэтому возможно ответ там.
Виталий: Ну раз фильтр перестал работать именно с 38-ой строки, значит, ответ там. Ага, фильтрация прекращает работать, как только встречается пустая строка!
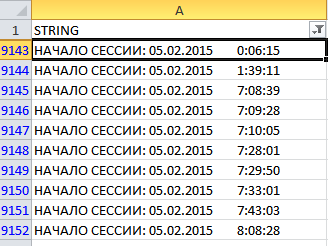
Олег: Значит, просто выделим всю таблицу и отфильтруем пустые строки! Всё, теперь все сработало так, как хотелось! Получилась выборка строк, содержащих текст «НАЧАЛО СЕССИИ:».
Виталий: В принципе уже можно сказать, что получили то, что требовалось. Но в таком виде вся информация по отдельной сессии находится в одной ячейке. А если потребуется дальнейшая ее обработка, например, фильтрации по времени или датам? Пожалуй, это было бы очень неудобно. Хорошо бы выделить дату и время в отдельные ячейки.
Олег: Время – деньги! Пожалуй, когда копаешься в логах банкомата, эта фраза приобретает особую прелесть… Что ж, давайте я расскажу вам немного о работе со строками в Excel.
Итак, каждый символ в строке имеет свою позицию, выраженную в виде смещения от начала строки. Все строки имеют конечную длину. Строки можно складывать, причем при сложении символы просто дописываются, т.е. если есть две строки «С1» и «С2», то при сложении первой и второй будет получена строка «С1С2». Из строки можно выделить произвольное число символов с любой позиции.
Что нам дает эта теория? Это дает нам возможность разобрать строку на отдельные составляющие, но для начала выясним: что и где у нас в строке.
Итак, в нашей строке:
- Подстрока «НАЧАЛО СЕССИИ: » занимает 15 символов, начиная с первой позиции.
- С позиции 16 хранится 10 символов даты.
- С позиции 26 располагается 7-8 пробельных символов, после которых хранятся символы времени, длина которых также не постоянна: она может быть либо 7, либо 8 символов. Количество пробелов зависит о того, сколько в строке указано часов. Если часов от 0 до 9, то пробелов будет 8, в остальных случаях – 7. Соответственно, длина времени также зависит от того, сколько указано часов. Если часов от 0 до 9, то длина будет 7 символов, иначе 8. Я даже нарисовал картинку, которая показывает, как хранятся строки и какие позиции занимают символы строки.

Виталий: Ну дальше понятно! Для получения части строки в MS Excel существуют чудесная функция ПСТР!
Функция ПСТР возвращает заданное число знаков из текстовой строки, начиная с указанной позиции.
Синтаксис:
ПСТР(текст, начальная_позиция, число_знаков)
Для примера напишем формулу, которая возвращает дату для одной из наших строк:
=ПСТР(«НАЧАЛО СЕССИИ: 05.02.2015 6:47:19»;16;10)
Если вы вставите такую функцию в любую ячейку абсолютно любой книги MS Excel, то получите результат: 05.02.2015. Вы можете прямо сейчас запустить Excel, скопировать туда формулу и убедиться в результате.
Олег: Тогда для получения даты в отфильтрованном наборе данных, во второй ячейке столбца «B» напишем следующую формулу:
=ПСТР(A34;16;10)
Виталий: Замечательно! Теперь осталось получить время, и задача решена! Но со временем есть небольшая сложность: в строке после даты может быть либо шесть, либо семь пробельных символов. И как мы теперь вычислим позицию? Не хотелось бы каждую формулу писать вручную. Ведь если воспользоваться все той же функцией ПСТР, то мы, конечно, получим время. Однако это время будет совмещено с пробельными символами, а они явно лишние, так как при их наличии MS Excel будет воспринимать данные как строку, а не как время, и, соответственно, адьос фильтрация! Может есть какая-то функция, удаляющая пробелы?
Олег: СЖПРОБЕЛЫ!
Виталий: Чего-чего? С тобой всё в порядке?!
Олег: Да функция это такая – СЖПРОБЕЛЫ. Не очень благозвучно, конечно, но такая уж локализация.Удаляет из текста все пробелы, за исключением одиночных пробелов между словами. Так что для получения времени в отфильтрованном наборе данных во второй ячейке столбца «С» пишем следующую формулу:
=СЖПРОБЕЛЫ(ПСТР(A34;26;15))
Обратите внимание, что в приведенной формуле одна функция является аргументом для другой. MS Excel вполне допускает такое. Приоритет работы таких конструкций определяется скобочками по математическим законам – сначала вычисляются значения самых вложенных скобок, затем уровнем выше и т.д. В нашем случае, первой отработает функция ПСТР, а после функция СЖПРОБЕЛЫ.
Итак, мы написали две формулы и разметили их в двух ячейках столбцов «B» и «C» соответственно. Для получения результата для всех строк, остается только размножить формулы столбцов «B» и «C» на все отфильтрованные строки.
Ну вот, и задачу решили, и до конца рабочего дня справились! Конечно, мне, как разработчику, не всегда по душе решать задачу, так сказать, «на коленке». Хочется, чтобы в результате появилось полноценное приложение, решающее какую-то глобальную потребность человечества, то чем смогут пользоваться другие люди…
Виталий: Но это все долго, а глобальных задач человечества мало. А вот задач, для которых решение нужно здесь и сейчас, вокруг полным-полно. И чтобы было максимально быстро при минимуме затрат. Как раз в такие моменты очень выручают офисные приложения и, конечно же, коллеги! Спасибо, Олег!
Олег: Рад был помочь! Не против, если я расскажу об этой задачке в NewTechAudit?
Виталий: Хорошо, только замени моё имя на Виталий. Всегда мечтал быть Виталием… Шутка!
Олег: Уже поздно…
Резюме
На данном, довольно простом примере, я показал, как с помощью офисного ПО можно собрать необходимую информацию. Но моей целью было не показать вам решение одного конкретного примера, а показать вам сам принцип, пути решения и собственные рассуждения J.
Задача по формированию выборки была решена за плюс-минус десять минут, на изложение пути решения ушло больше часа. Надеюсь, что мой опыт будет Вам полезен.